CloudNativePG: et PostgreSQL devient facile sur Kubernetes
Sommaire
Kubernetes est désormais la plate-forme privilégiée pour orchestrer les applications "sans état" aussi appelé "stateless". Les conteneurs qui ne stockent pas de données peuvent être détruits et recréés ailleurs sans impact. En revanche, la gestion d'applications "stateful" dans un environnement dynamique tel que Kubernetes peut être un véritable défi. Malgré le fait qu'il existe un nombre croissant de solutions de base de données "Cloud Native" (comme CockroachDB, TiDB, K8ssandra, Strimzi ...) et il y a de nombreux éléments à considérer lors de leur évaluation:
- Quelle est la maturité de l'opérateur? (Dynamisme et contributeurs, gouvernance du projet)
- Quels sont les resources personalisées disponibles ("custom resources"), quelles opérations permettent t-elles de réaliser?
- Quels sont les type de stockage disponibles: HDD / SSD, stockage local / distant?
- Que se passe-t-il lorsque quelque chose se passe mal: Quelle est le niveau de résilience de la solution?
- Sauvegarde et restauration: est-il facile d'effectuer et de planifier des sauvegardes?
- Quelles options de réplication et de mise à l'échelle sont disponibles?
- Qu'en est-il des limites de connexion et de concurrence, les pools de connexion?
- A propos de la supervision, quelles sont les métriques exposées et comment les exploiter?
J'étais à la recherche d'une solution permettant de gérer un serveur PostgreSQL. La base de données qui y serait hébergée est nécessaire pour un logiciel de réservation de billets nommé Alf.io. Nous sommes en effet en train d'organiser les Kubernetes Community Days France vous êtes tous conviés! 👐.
Je cherchais spécifiquement une solution indépendante d'un clouder (cloud agnostic) et l'un des principaux critères était la simplicité d'utilisation. Je connaissais déjà plusieurs opérateurs Kubernetes, et j'ai fini par évaluer une solution relativement récente: CloudNativePG.
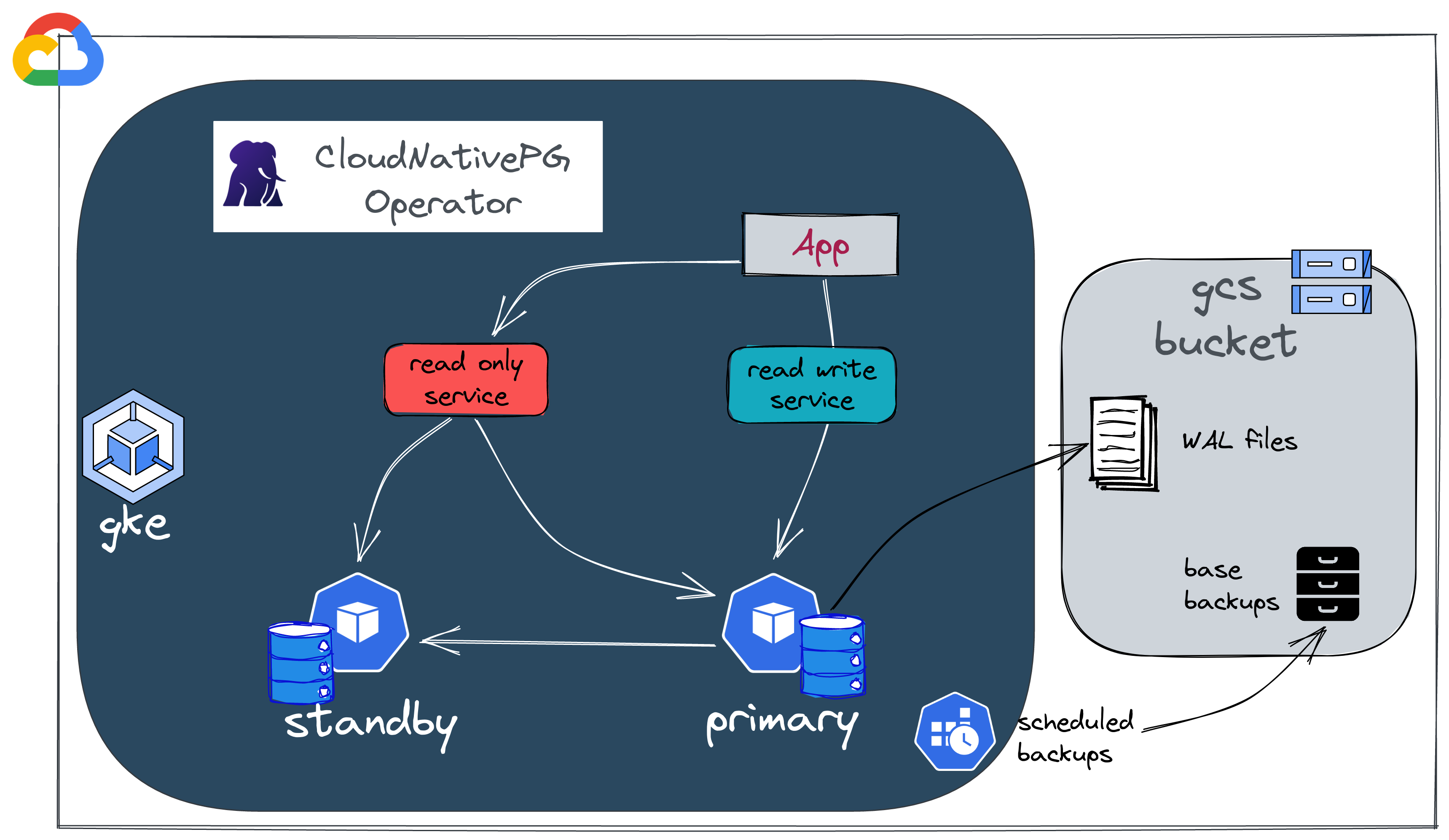
CloudNativepg est l'opérateur de Kubernetes qui couvre le cycle de vie complet d'un cluster de base de données PostgreSQL hautement disponible avec une architecture de réplication native en streaming.
Ce projet été créé par l'entreprise EnterpriseDB et a été soumis à la CNCF afin de rejoindre les projets Sandbox.
🎯 Notre objectif
Je vais donner ici une introduction aux principales fonctionnalités de CloudNativePG.
L'objectif est de:
- Créer une base de données PostgreSQL sur un cluster GKE,
- Ajouter une instance secondaire (réplication)
- Exécuter quelques tests de résilience.
Nous verrons également comment tout cela se comporte en terme de performances et quels sont les outils de supervision disponibles. Enfin, nous allons jeter un œil aux méthodes de sauvegarde/restauration.
Dans cet article, nous allons tout créer et tout mettre à jour manuellement. Mais dans un environnement de production, il est conseillé d'utiliser un moteur GitOps, par exemple Flux (sujet couvert dans un article précédent).
Si vous souhaitez voir un exemple complet, vous pouvez consulter le dépôt git KCD France infrastructure.
Toutes les resources de cet article sont dans ce dépôt.
☑️ Prérequis
📥 Outils
gcloud SDK: Nous allons déployer sur Google Cloud (en particulier sur GKE) et, pour ce faire, nous devrons créer quelques ressources dans notre projet GCP. Nous aurons donc besoin du SDK et de la CLI Google Cloud. Il est donc nécessaire de l'installer en suivant cette documentation.
kubectl plugin: Pour faciliter la gestion des clusters, il existe un plugin
kubectlqui donne des informations synthétiques sur l'instance PostgreSQL et permet aussi d'effectuer certaines opérations. Ce plugin peut être installé en utilisant krew:
1kubectl krew install cnpg
☁️ Créer les resources Google Cloud
Avant de créer notre instance PostgreSQL, nous devons configurer certaines choses:
- Nous avons besoin d'un cluster Kubernetes. (Cet article suppose que vous avez déjà pris soin de provisionner un cluster GKE)
- Nous allons créer un bucket (Google Cloud Storage) pour stocker les sauvegardes et Fichiers WAL.
- Nous configurerons les permissions pour nos pods afin qu'ils puissent écrire dans ce bucket.
Créer le bucket à l'aide de CLI gcloud
1gcloud storage buckets create --location=eu --default-storage-class=coldline gs://cnpg-ogenki
2Creating gs://cnpg-ogenki/...
3
4gcloud storage buckets describe gs://cnpg-ogenki
5[...]
6name: cnpg-ogenki
7owner:
8 entity: project-owners-xxxx0008
9projectNumber: 'xxx00008'
10rpo: DEFAULT
11selfLink: https://www.googleapis.com/storage/v1/b/cnpg-ogenki
12storageClass: STANDARD
13timeCreated: '2022-10-15T19:27:54.364000+00:00'
14updated: '2022-10-15T19:27:54.364000+00:00'
Nous allons maintenant configurer les permissions afin que les pods (PostgreSQL Server) puissent permettant écrire/lire à partir du bucket grâce à Workload Identity.
Workload Identity doit être activé au niveau du cluster GKE. Afin de vérifier que le cluster est bien configuré, vous pouvez lancer la commande suivante:
1gcloud container clusters describe <cluster_name> --format json --zone <zone> | jq .workloadIdentityConfig
2{
3 "workloadPool": "{{ gcp_project }}.svc.id.goog"
4}
Créer un compte de service Google Cloud
1gcloud iam service-accounts create cloudnative-pg --project={{ gcp_project }}
2Created service account [cloudnative-pg].
Attribuer au compte de service la permission storage.admin
1gcloud projects add-iam-policy-binding {{ gcp_project }} \
2--member "serviceAccount:cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com" \
3--role "roles/storage.admin"
4[...]
5- members:
6 - serviceAccount:cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com
7 role: roles/storage.admin
8etag: BwXrGA_VRd4=
9version: 1
Autoriser le compte de service (Attention il s'agit là du compte de service au niveau Kubernetes) afin d'usurper le compte de service IAM.
ℹ️ Assurez-vous d'utiliser le format approprié serviceAccount:{{ gcp_project }}.svc.id.goog[{{ kubernetes_namespace }}/{{ kubernetes_serviceaccount }}]
1gcloud iam service-accounts add-iam-policy-binding cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com \
2--role roles/iam.workloadIdentityUser --member "serviceAccount:{{ gcp_project }}.svc.id.goog[demo/ogenki]"
3Updated IAM policy for serviceAccount [cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com].
4bindings:
5- members:
6 - serviceAccount:{{ gcp_project }}.svc.id.goog[demo/ogenki]
7 role: roles/iam.workloadIdentityUser
8etag: BwXrGBjt5kQ=
9version: 1
Nous sommes prêts à créer les ressources Kubernetes 💪
🔑 Créer les secrets pour les utilisateurs PostgreSQL
Nous devons créer les paramètres d'authentification des utilisateurs qui seront créés pendant la phase de "bootstrap" (nous y reviendrons par la suite): le superutilisateur et le propriétaire de base de données nouvellement créé.
1kubectl create secret generic cnpg-mydb-superuser --from-literal=username=postgres --from-literal=password=foobar --namespace demo
2secret/cnpg-mydb-superuser created
1kubectl create secret generic cnpg-mydb-user --from-literal=username=smana --from-literal=password=barbaz --namespace demo
2secret/cnpg-mydb-user created
🛠️ Déployer l'opérateur CloudNativePG avec Helm
Ici nous utiliserons le chart Helm pour déployer CloudNativePG:
1helm repo add cnpg https://cloudnative-pg.github.io/charts
2
3helm upgrade --install cnpg --namespace cnpg-system \
4--create-namespace charts/cloudnative-pg
5
6kubectl get po -n cnpg-system
7NAME READY STATUS RESTARTS AGE
8cnpg-74488f5849-8lhjr 1/1 Running 0 6h17m
Cela installe aussi quelques resources personnalisées (Custom Resources Definitions)
1kubectl get crds | grep cnpg.io
2backups.postgresql.cnpg.io 2022-10-08T16:15:14Z
3clusters.postgresql.cnpg.io 2022-10-08T16:15:14Z
4poolers.postgresql.cnpg.io 2022-10-08T16:15:14Z
5scheduledbackups.postgresql.cnpg.io 2022-10-08T16:15:14Z
Pour une liste complète des paramètres possibles, veuillez vous référer à la doc de l'API.
🚀 Créer un serveur PostgreSQL

Nous pouvons désormais créer notre première instance en utilisant une resource personnalisée Cluster. La définition suivante est assez simple:
Nous souhaitons démarrer un serveur PostgreSQL, créer automatiquement une base de données nommée mydb et configurer les informations d'authentification en utilisant les secrets créés précédemment.
1apiVersion: postgresql.cnpg.io/v1
2kind: Cluster
3metadata:
4 name: ogenki
5 namespace: demo
6spec:
7 description: "PostgreSQL Demo Ogenki"
8 imageName: ghcr.io/cloudnative-pg/postgresql:14.5
9 instances: 1
10
11 bootstrap:
12 initdb:
13 database: mydb
14 owner: smana
15 secret:
16 name: cnpg-mydb-user
17
18 serviceAccountTemplate:
19 metadata:
20 annotations:
21 iam.gke.io/gcp-service-account: cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com
22
23 superuserSecret:
24 name: cnpg-mydb-superuser
25
26 storage:
27 storageClass: standard
28 size: 10Gi
29
30 backup:
31 barmanObjectStore:
32 destinationPath: "gs://cnpg-ogenki"
33 googleCredentials:
34 gkeEnvironment: true
35 retentionPolicy: "30d"
36
37 resources:
38 requests:
39 memory: "1Gi"
40 cpu: "500m"
41 limits:
42 memory: "1Gi"
Créer le namespace où notre instance postgresql sera déployée
1kubectl create ns demo
2namespace/demo created
Adapdez le fichier YAML ci-dessus vos besoins et appliquez comme suit:
1kubectl apply -f cluster.yaml
2cluster.postgresql.cnpg.io/ogenki created
Vous remarquerez que le cluster sera en phase Initializing. Nous allons utiliser le plugin CNPG pour la première fois afin de vérifier son état. Cet outil deviendra par la suite notre meilleur ami pour afficher une vue synthétique de l'état du cluster.
1kubectl cnpg status ogenki -n demo
2Cluster Summary
3Primary server is initializing
4Name: ogenki
5Namespace: demo
6PostgreSQL Image: ghcr.io/cloudnative-pg/postgresql:14.5
7Primary instance: (switching to ogenki-1)
8Status: Setting up primary Creating primary instance ogenki-1
9Instances: 1
10Ready instances: 0
11
12Certificates Status
13Certificate Name Expiration Date Days Left Until Expiration
14---------------- --------------- --------------------------
15ogenki-ca 2023-01-13 20:02:40 +0000 UTC 90.00
16ogenki-replication 2023-01-13 20:02:40 +0000 UTC 90.00
17ogenki-server 2023-01-13 20:02:40 +0000 UTC 90.00
18
19Continuous Backup status
20First Point of Recoverability: Not Available
21No Primary instance found
22Streaming Replication status
23Not configured
24
25Instances status
26Name Database Size Current LSN Replication role Status QoS Manager Version Node
27---- ------------- ----------- ---------------- ------ --- --------------- ----
immédiatement après la déclaration de notre nouveau Cluster, une action de bootstrap est lancée.
Dans notre exemple, nous créons une toute nouvelle base de données nommée mydb avec un propriétaire smana dont les informations d'authentification viennent du secret créé précédemment.
1[...]
2 bootstrap:
3 initdb:
4 database: mydb
5 owner: smana
6 secret:
7 name: cnpg-mydb-user
8[...]
1kubectl get po -n demo
2NAME READY STATUS RESTARTS AGE
3ogenki-1 0/1 Running 0 55s
4ogenki-1-initdb-q75cz 0/1 Completed 0 2m32s
Après quelques secondes, le cluster change de statut et devient Ready (configuré et prêt à l'usage) 👏
1kubectl cnpg status ogenki -n demo
2Cluster Summary
3Name: ogenki
4Namespace: demo
5System ID: 7154833472216277012
6PostgreSQL Image: ghcr.io/cloudnative-pg/postgresql:14.5
7Primary instance: ogenki-1
8Status: Cluster in healthy state
9Instances: 1
10Ready instances: 1
11
12[...]
13
14Instances status
15Name Database Size Current LSN Replication role Status QoS Manager Version Node
16---- ------------- ----------- ---------------- ------ --- --------------- ----
17ogenki-1 33 MB 0/17079F8 Primary OK Burstable 1.18.0 gke-kcdfrance-main-np-0e87115b-xczh
Il existe de nombreuses façons de bootstrap un cluster. Par exemple, la restauration d'une sauvegarde dans une toute nouvelle instance ou en exécutant du code SQL ... Plus d'infos ici.
🩹 Instance de secours et résilience
Dans les architectures postgresql traditionnelles, nous trouvons généralement un composant supplémentaire pour gérer la haute disponibilité (ex: Patroni). Un particularité de l'opérateur CloudNativePG est qu'il bénéficie des fonctionnalités de base de Kubernetes et s'appuie sur un composant nommé Postgres instance manager.
Ajoutez une instance de secours ("standby") en définissant le nombre de répliques sur 2.

1kubectl edit cluster -n demo ogenki
2cluster.postgresql.cnpg.io/ogenki edited
1apiVersion: postgresql.cnpg.io/v1
2kind: Cluster
3[...]
4spec:
5 instances: 2
6[...]
L'opérateur remarque immédiatement le changement, ajoute une instance de secours et démarre le processus de réplication.
1kubectl cnpg status -n demo ogenki
2Cluster Summary
3Name: ogenki
4Namespace: demo
5System ID: 7155095145869606932
6PostgreSQL Image: ghcr.io/cloudnative-pg/postgresql:14.5
7Primary instance: ogenki-1
8Status: Creating a new replica Creating replica ogenki-2-join
9Instances: 2
10Ready instances: 1
11Current Write LSN: 0/1707A30 (Timeline: 1 - WAL File: 000000010000000000000001)
1kubectl get po -n demo
2NAME READY STATUS RESTARTS AGE
3ogenki-1 1/1 Running 0 3m16s
4ogenki-2-join-xxrwx 0/1 Pending 0 82s
Après un certain temps (qui dépend de la quantité de données à répliquer), l'instance de secours devient opérationnelle et nous pouvons voir les statistiques de réplication.
1kubectl cnpg status -n demo ogenki
2Cluster Summary
3Name: ogenki
4Namespace: demo
5System ID: 7155095145869606932
6PostgreSQL Image: ghcr.io/cloudnative-pg/postgresql:14.5
7Primary instance: ogenki-1
8Status: Cluster in healthy state
9Instances: 2
10Ready instances: 2
11Current Write LSN: 0/3000060 (Timeline: 1 - WAL File: 000000010000000000000003)
12
13[...]
14
15Streaming Replication status
16Name Sent LSN Write LSN Flush LSN Replay LSN Write Lag Flush Lag Replay Lag State Sync State Sync Priority
17---- -------- --------- --------- ---------- --------- --------- ---------- ----- ---------- -------------
18ogenki-2 0/3000060 0/3000060 0/3000060 0/3000060 00:00:00 00:00:00 00:00:00 streaming async 0
19
20Instances status
21Name Database Size Current LSN Replication role Status QoS Manager Version Node
22---- ------------- ----------- ---------------- ------ --- --------------- ----
23ogenki-1 33 MB 0/3000060 Primary OK Burstable 1.18.0 gke-kcdfrance-main-np-0e87115b-76k7
24ogenki-2 33 MB 0/3000060 Standby (async) OK Burstable 1.18.0 gke-kcdfrance-main-np-0e87115b-xszc
Nous allons désormais éffectuer ce que l'on appelle un "Switchover": Nous allons promouvoir l'instance de secours en instance primaire.

Le plugin cnpg permet de le faire de façon impérative, en utilisant la ligne de commande suivante:
1kubectl cnpg promote ogenki ogenki-2 -n demo
2Node ogenki-2 in cluster ogenki will be promoted
Dans mon cas, le basculement était vraiment rapide. Nous pouvons vérifier que l'instance ogenki-2 est devenu primaire et que la réplication est effectuée dans l'autre sens.
1kubectl cnpg status -n demo ogenki
2[...]
3Status: Switchover in progress Switching over to ogenki-2
4Instances: 2
5Ready instances: 1
6[...]
7Streaming Replication status
8Name Sent LSN Write LSN Flush LSN Replay LSN Write Lag Flush Lag Replay Lag State Sync State Sync Priority
9---- -------- --------- --------- ---------- --------- --------- ---------- ----- ---------- -------------
10ogenki-1 0/4004CA0 0/4004CA0 0/4004CA0 0/4004CA0 00:00:00 00:00:00 00:00:00 streaming async 0
11
12Instances status
13Name Database Size Current LSN Replication role Status QoS Manager Version Node
14---- ------------- ----------- ---------------- ------ --- --------------- ----
15ogenki-2 33 MB 0/4004CA0 Primary OK Burstable 1.18.0 gke-kcdfrance-main-np-0e87115b-xszc
16ogenki-1 33 MB 0/4004CA0 Standby (async) OK Burstable 1.18.0 gke-kcdfrance-main-np-0e87115b-76k7
Maintenant, provoquons un Failover en supprimant le pod principal

1kubectl delete po -n demo --grace-period 0 --force ogenki-2
2Warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely.
3pod "ogenki-2" force deleted
1Cluster Summary
2Name: ogenki
3Namespace: demo
4System ID: 7155095145869606932
5PostgreSQL Image: ghcr.io/cloudnative-pg/postgresql:14.5
6Primary instance: ogenki-1
7Status: Failing over Failing over from ogenki-2 to ogenki-1
8Instances: 2
9Ready instances: 1
10Current Write LSN: 0/4005D98 (Timeline: 3 - WAL File: 000000030000000000000004)
11
12[...]
13Instances status
14Name Database Size Current LSN Replication role Status QoS Manager Version Node
15---- ------------- ----------- ---------------- ------ --- --------------- ----
16ogenki-1 33 MB 0/40078D8 Primary OK Burstable 1.18.0 gke-kcdfrance-main-np-0e87115b-76k7
17ogenki-2 - - - pod not available Burstable - gke-kcdfrance-main-np-0e87115b-xszc
Quelques secondes plus tard le cluster devient opérationnel à nouveau.
1kubectl get cluster -n demo
2NAME AGE INSTANCES READY STATUS PRIMARY
3ogenki 13m 2 2 Cluster in healthy state ogenki-1
Jusqu'ici tout va bien, nous avons pu faire quelques tests de la haute disponibilité et c'était assez probant 😎.
👁️ Supervision
Nous allons utiliser la Stack Prometheus. Nous ne couvrirons pas son installation dans cet article. Si vous voulez voir comment l'installer avec Flux, vous pouvez jeter un oeil à cet exemple.
Pour récupérer les métriques de notre instance, nous devons créer un PodMonitor.
1apiVersion: monitoring.coreos.com/v1
2kind: PodMonitor
3metadata:
4 labels:
5 prometheus-instance: main
6 name: cnpg-ogenki
7 namespace: demo
8spec:
9 namespaceSelector:
10 matchNames:
11 - demo
12 podMetricsEndpoints:
13 - port: metrics
14 selector:
15 matchLabels:
16 postgresql: ogenki
Nous pouvons ensuite ajouter le tableau de bord Grafana disponible ici.
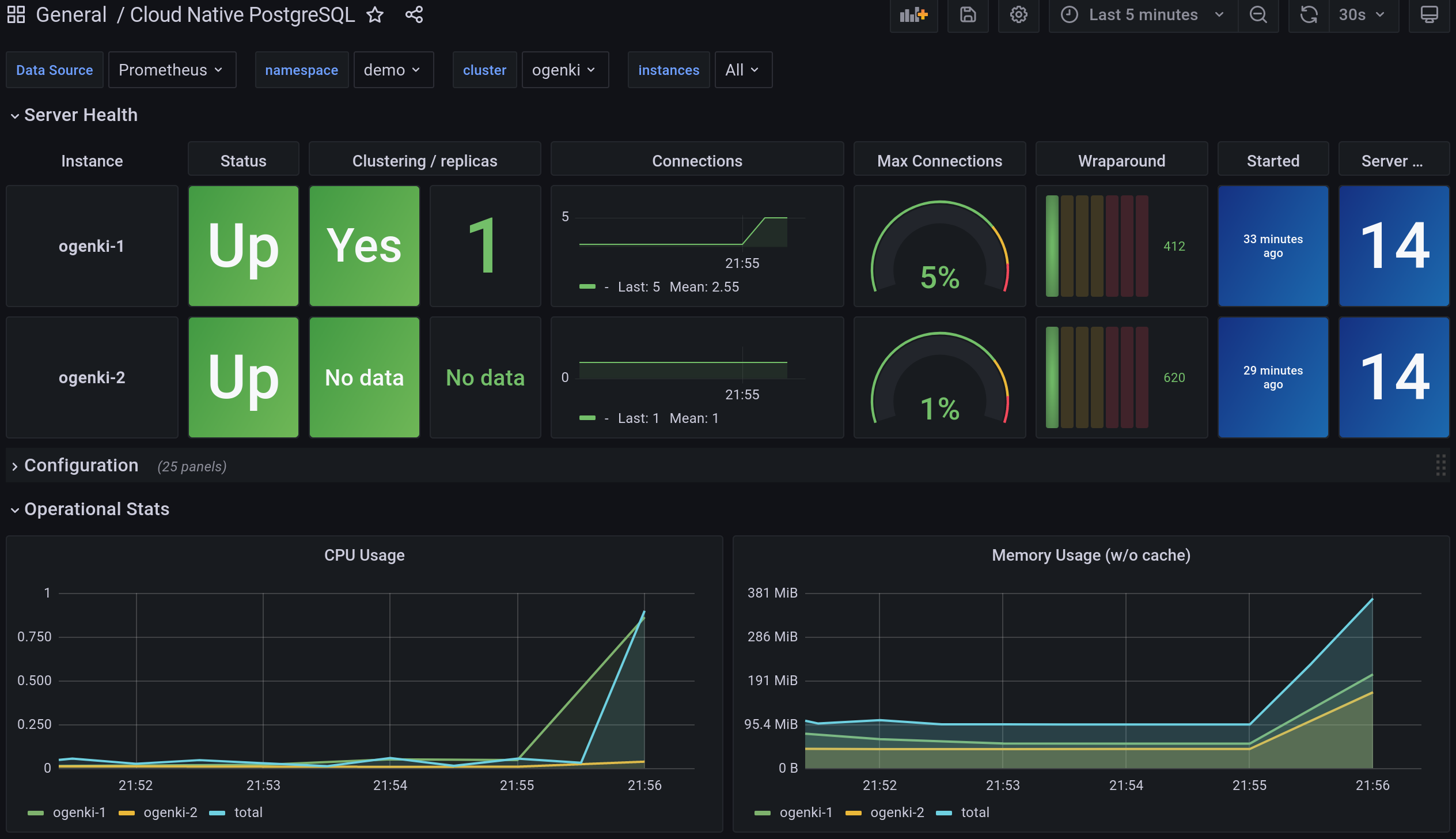
Enfin, vous souhaiterez peut-être configurer des alertes et vous pouvez créer un PrometheusRule en utilisant ces règles.
🔥 Performances and benchmark
Mise à jour: Il est désormais possible de faire un test de performance avec le plugin cnpg
Afin de connaitre les limites de votre serveur, vous devriez faire un test de performances et de conserver une base de référence pour de futures améliorations.
Au sujet des performances, il existe de nombreux domaines d'amélioration sur lesquels nous pouvons travailler.Cela dépend principalement de l'objectif que nous voulons atteindre. En effet, nous ne voulons pas perdre du temps et de l'argent pour les performances dont nous n'aurons probablement jamais besoin.
Voici les principaux éléments à analyser:
- Tuning de la configuration PostgreSQL
- Resources systèmes (cpu et mémoire)
- Types de Disque : IOPS, stockage locale (local-volume-provisioner),
- Disques dédiées pour les WAL et les données PG_DATA
- "Pooling" de connexions PGBouncer. CloudNativePG fourni une resource personnalisée
Poolerqui permet de configurer cela facilement. - Optimisation de la base de données, analyser les plans d'exécution grâce à explain, utiliser l'extension
pg_stat_statement...

Tout d'abord, nous ajouterons des "labels" aux nœuds afin d'exécuter la commande pgbench sur différentes machines de celles hébergeant la base de données.
1PG_NODE=$(kubectl get po -n demo -l postgresql=ogenki,role=primary -o jsonpath={.items[0].spec.nodeName})
2kubectl label node ${PG_NODE} workload=postgresql
3node/gke-kcdfrance-main-np-0e87115b-vlzm labeled
4
5
6# Choose any other node different than the ${PG_NODE}
7kubectl label node gke-kcdfrance-main-np-0e87115b-p5d7 workload=pgbench
8node/gke-kcdfrance-main-np-0e87115b-p5d7 labeled
Et nous déploierons le chart Helm comme suit
1git clone git@github.com:EnterpriseDB/cnp-bench.git
2cd cnp-bench
3
4cat > pgbench-benchmark/myvalues.yaml <<EOF
5cnp:
6 existingCluster: true
7 existingHost: ogenki-rw
8 existingCredentials: cnpg-mydb-superuser
9 existingDatabase: mydb
10
11pgbench:
12 # Node where to run pgbench
13 nodeSelector:
14 workload: pgbench
15 initialize: true
16 scaleFactor: 1
17 time: 600
18 clients: 10
19 jobs: 1
20 skipVacuum: false
21 reportLatencies: false
22EOF
23
24helm upgrade --install -n demo pgbench -f pgbench-benchmark/myvalues.yaml pgbench-benchmark/
Il existe différents services selon que vous souhaitez lire et écrire ou de la lecture seule.
1kubectl get ep -n demo
2NAME ENDPOINTS AGE
3ogenki-any 10.64.1.136:5432,10.64.1.3:5432 15d
4ogenki-r 10.64.1.136:5432,10.64.1.3:5432 15d
5ogenki-ro 10.64.1.136:5432 15d
6ogenki-rw 10.64.1.3:5432 15d
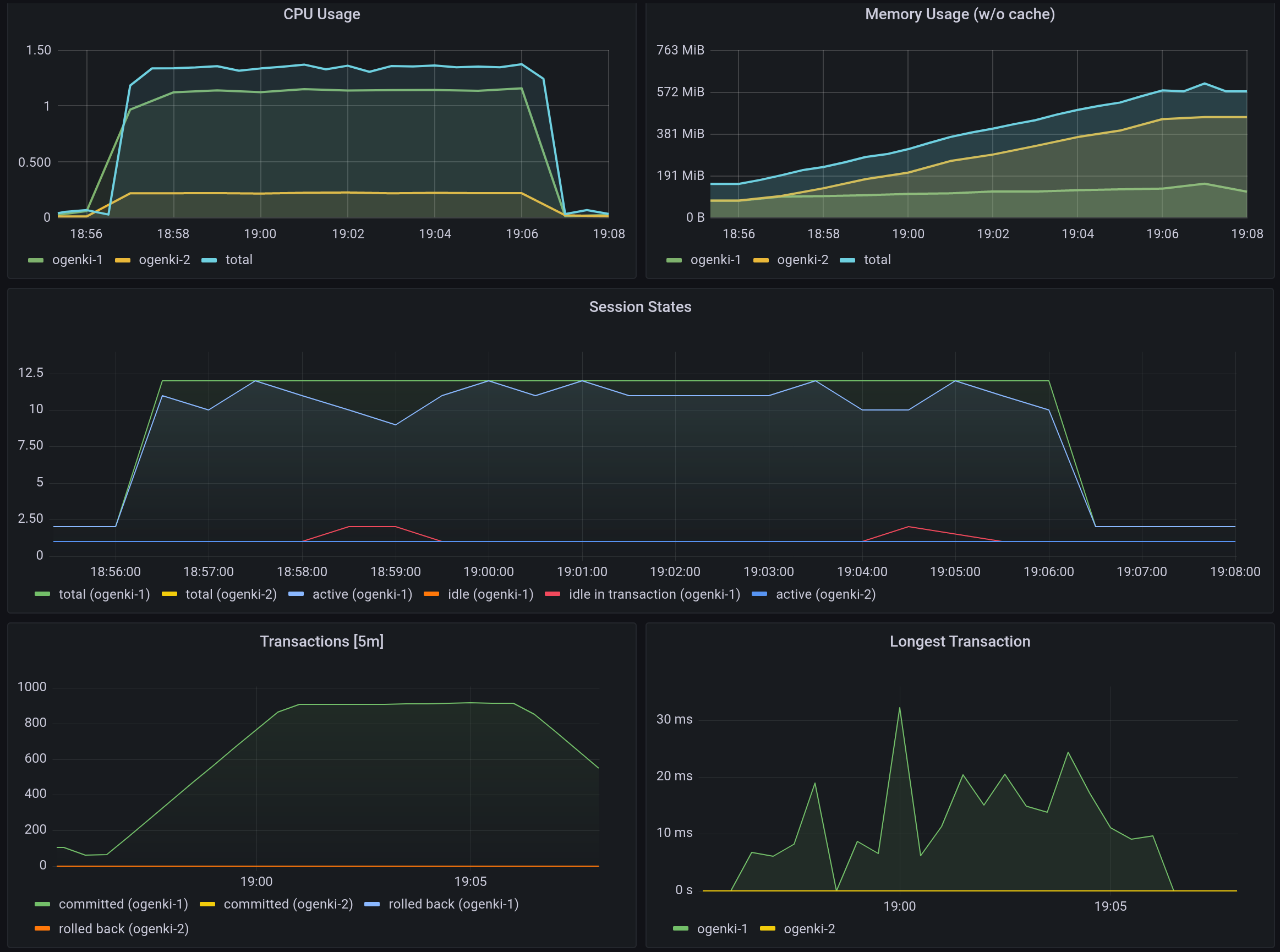
1kubectl logs -n demo job/pgbench-pgbench-benchmark -f
2Defaulted container "pgbench" out of: pgbench, wait-for-cnp (init), pgbench-init (init)
3pgbench (14.1, server 14.5 (Debian 14.5-2.pgdg110+2))
4starting vacuum...end.
5transaction type: <builtin: TPC-B (sort of)>
6scaling factor: 1
7query mode: simple
8number of clients: 10
9number of threads: 1
10duration: 600 s
11number of transactions actually processed: 545187
12latency average = 11.004 ms
13initial connection time = 111.585 ms
14tps = 908.782896 (without initial connection time)
💽 Sauvegarde and restaurations
Le fait de pouvoir stocker des sauvegarde et fichiers WAL dans le bucket GCP est possible car nous avons attribué les autorisations en utilisant une annotation présente dans le ServiceAccount utilisé par le cluster
1serviceAccountTemplate:
2 metadata:
3 annotations:
4 iam.gke.io/gcp-service-account: cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com
Nous pouvons d'abord déclencher une sauvegarde on demand à l'aide de la ressource personnalisée Backup
1apiVersion: postgresql.cnpg.io/v1
2kind: Backup
3metadata:
4 name: ogenki-now
5 namespace: demo
6spec:
7 cluster:
8 name: ogenki
1kubectl apply -f backup.yaml
2backup.postgresql.cnpg.io/ogenki-now created
3
4kubectl get backup -n demo
5NAME AGE CLUSTER PHASE ERROR
6ogenki-now 36s ogenki completed
Si vous jetez un œil au contenu du bucket GCS, vous verrez un nouveau répertoire qui stocke les sauvegardes de base ("base backups").
1gcloud storage ls gs://cnpg-ogenki/ogenki/base
2gs://cnpg-ogenki/ogenki/base/20221023T130327/
Mais la plupart du temps, nous préfererons configurer une sauvegarde planifiée ("scheduled"). Ci-dessous un exemple pour une sauvegarde quotidienne:
1apiVersion: postgresql.cnpg.io/v1
2kind: ScheduledBackup
3metadata:
4 name: ogenki-daily
5 namespace: demo
6spec:
7 backupOwnerReference: self
8 cluster:
9 name: ogenki
10 schedule: 0 0 0 * * *
Les restaurations ne peuvent être effectuées que sur de nouvelles instances. Ici, nous utiliserons la sauvegarde que nous avions créée précédemment afin d'initialiser une toute nouvelle instance.
1gcloud iam service-accounts add-iam-policy-binding cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com \
2--role roles/iam.workloadIdentityUser --member "serviceAccount:{{ gcp_project }}.svc.id.goog[demo/ogenki-restore]"
3Updated IAM policy for serviceAccount [cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com].
4bindings:
5- members:
6 - serviceAccount:{{ gcp_project }}.svc.id.goog[demo/ogenki-restore]
7 - serviceAccount:{{ gcp_project }}.svc.id.goog[demo/ogenki]
8 role: roles/iam.workloadIdentityUser
9etag: BwXrs755FPA=
10version: 1
1apiVersion: postgresql.cnpg.io/v1
2kind: Cluster
3metadata:
4 name: ogenki-restore
5 namespace: demo
6spec:
7 instances: 1
8
9 serviceAccountTemplate:
10 metadata:
11 annotations:
12 iam.gke.io/gcp-service-account: cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com
13
14 storage:
15 storageClass: standard
16 size: 10Gi
17
18 resources:
19 requests:
20 memory: "1Gi"
21 cpu: "500m"
22 limits:
23 memory: "1Gi"
24
25 superuserSecret:
26 name: cnpg-mydb-superuser
27
28 bootstrap:
29 recovery:
30 backup:
31 name: ogenki-now
Nous notons qu'un pod se charge immédiatement de la restauration complète ("full recovery").
1kubectl get po -n demo
2NAME READY STATUS RESTARTS AGE
3ogenki-1 1/1 Running 1 (18h ago) 18h
4ogenki-2 1/1 Running 0 18h
5ogenki-restore-1 0/1 Init:0/1 0 0s
6ogenki-restore-1-full-recovery-5p4ct 0/1 Completed 0 51s
Le nouveau cluster devient alors opérationnel ("Ready").
1kubectl get cluster -n demo
2NAME AGE INSTANCES READY STATUS PRIMARY
3ogenki 18h 2 2 Cluster in healthy state ogenki-1
4ogenki-restore 80s 1 1 Cluster in healthy state ogenki-restore-1
🧹 Nettoyage
Suppression du cluster
1kubectl delete cluster -n demo ogenki ogenki-restore
2cluster.postgresql.cnpg.io "ogenki" deleted
3cluster.postgresql.cnpg.io "ogenki-restore" deleted
Supprimer le service IAM
1gcloud iam service-accounts delete cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com
2You are about to delete service account [cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com].
3
4Do you want to continue (Y/n)? y
5
6deleted service account [cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com]
💭 Conclusion
Je viens tout juste de découvrir CloudNativePG et je n'ai fait qu'en percevoir la surface, mais une chose est sûre: la gestion d'une instance PostgreSQL est vraiment facilitée. Cependant, le choix d'une solution de base de données est une décision complexe. Il faut prendre en compte le cas d'usage, les contraintes de l'entreprise, la criticité de l'application et les compétences des équipes opérationnelles. Il existe de nombreuses options: bases de données gérées par le fournisseur Cloud, installation traditionnelle sur serveur baremetal, solutions distribuées ...
Nous pouvons également envisager d'utiliser Crossplane et une Composition pour fournir un niveau d'abstraction supplémentaire afin de déclarer des bases de données des fournisseurs Cloud, mais cela nécessite plus de configuration.
CloudNativePG sort du lot par sa simplicité: Super facile à exécuter et à comprendre. De plus, la documentation est excellente (l'une des meilleures que j'aie jamais vues!), Surtout pour un si jeune projet open source (cela aidera peut être pour être accepté en tant que projet "Sandbox" CNCF 🤞).
Si vous voulez en savoir plus, il y avait une présentation à ce sujet à KubeCon NA 2022.