Agentic Coding : concepts et cas concrets appliqués au Platform Engineering
Sommaire
Nous le voyons bien, nous assistons à un réel bouleversement provoqué par l'utilisation de l'IA. Ce domaine évolue à une telle vitesse qu'il devient presque impossible de suivre toutes les nouveautés. Quant à mesurer l'impact sur notre quotidien et notre façon de travailler, il est encore trop tôt pour le dire. Une chose est sûre cependant : dans la tech, c'est une révolution !
Ici, je vais vous présenter une utilisation pratique dans le métier du "Platform Engineering" avec une exploration de l'utilisation d'un "coding agent" dans certaines tâches communes de notre métier.
Mais surtout, je vais tenter de vous démontrer par des cas concrets que cette nouvelle façon de travailler augmente réellement notre productivité. Si si !
🎯 Objectifs de cet article
- Comprendre ce qu'est un coding agent
- Découvrir les concepts clés : tokens, MCPs, skills, agents
- Cas concrets d'utilisation dans le platform engineering
- Réflexions sur les limites, pièges à éviter et alternatives
- Pour les tips et workflows découverts au fil de mon utilisation, consultez l'article dédié
 | Les exemples qui suivent sont issus de mon travail sur le repository Cloud Native Ref. Il s'agit d'une plateforme complète combinant EKS, Cilium, VictoriaMetrics, Crossplane, Flux et bien d'autres outils. |
Si vous connaissez déjà les fondamentaux des coding agents, des tokens et des MCPs, passez directement aux cas concrets pour le Platform Engineering.
🧠 L'intérêt des Coding Agents?
Le fonctionnement d’un agent
Vous utilisez probablement déjà ChatGPT, LeChat ou Gemini pour poser des questions. C'est cool, mais ça reste du one-shot : vous posez une question, vous obtenez une réponse dont la pertinence dépendra de la qualité de votre prompt.
Un coding agent fonctionne différemment. Il exécute des outils en boucle pour atteindre un objectif. C'est ce qu'on appelle une boucle agentique.
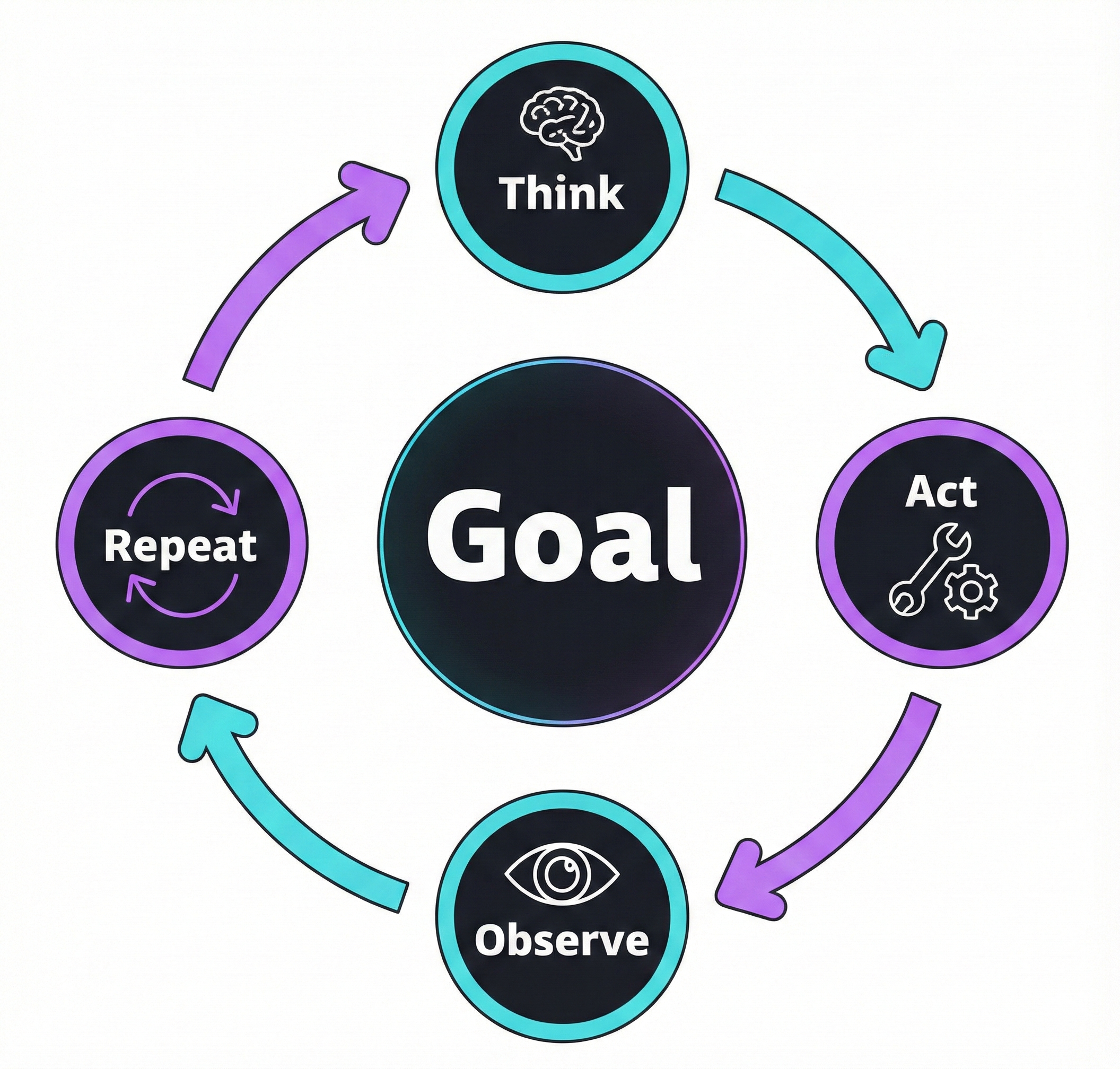
Le cycle est simple : raisonner → agir → observer → répéter. L'agent appelle un outil, analyse le résultat, puis décide de la prochaine action. Il est donc essentiel qu'il ait accès au retour de chaque action — une erreur de compilation, un test qui échoue, une sortie inattendue. Cette capacité à réagir et itérer de manière autonome sur notre environnement local est ce qui fait toute la différence avec un simple chatbot.
Un coding agent combine plusieurs composants :
- LLM : Le "cerveau" qui raisonne (Claude Opus 4.6, Gemini 3 Pro, Devstral 2...)
- Tools : Les actions possibles (lire/écrire des fichiers, exécuter des commandes, chercher sur le web...)
- Memory : Le contexte conservé (fichiers
CLAUDE.md,AGENTS.md,GEMINI.md... selon l'outil, plus l'historique de conversation) - Planning : La capacité à décomposer une tâche complexe en sous-étapes
Bien choisir son modèle, dur de suivre la cadence 🤯
De nouveaux modèles ainsi que de nouvelles versions apparaissent à une vitesse effrénée. Il faut cependant être vigilant dans le choix du modèle car l'efficacité (qualité de code, hallucinations, contexte à jour) peut radicalement différer.
Le benchmark SWE-bench Verified est devenu la référence pour évaluer les capacités des modèles en développement logiciel. Il mesure la capacité à résoudre de vrais bugs issus de repositories GitHub et permet de nous aider à faire notre choix.
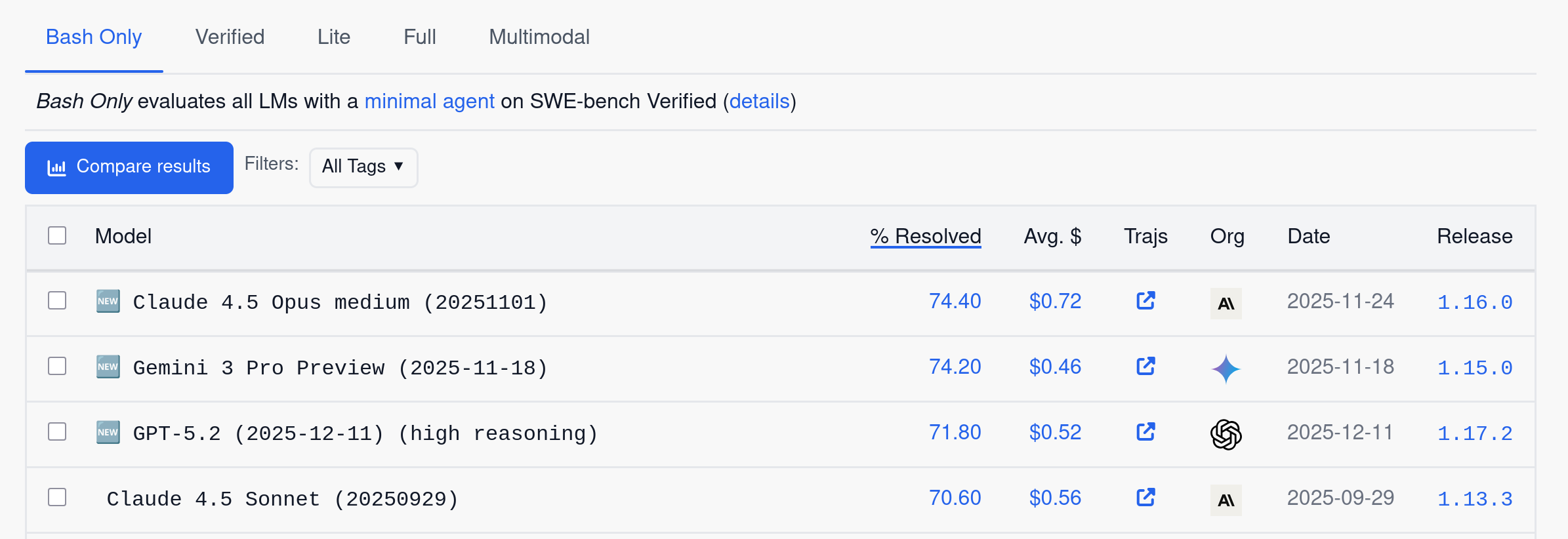
Consultez vals.ai pour les derniers résultats indépendants. Au moment de la rédaction, Claude Opus 4.6 mène avec 79.2%, talonné par Gemini 3 Flash (76.2%) et GPT-5.2 (75.4%).
En pratique, les meilleurs modèles actuels sont tous suffisamment performants pour la plupart des tâches de Platform Engineering.
Boris Cherny, créateur de Claude Code, a partagé son point de vue sur le choix du modèle (à propos d'Opus 4.5 — le raisonnement reste valable) :
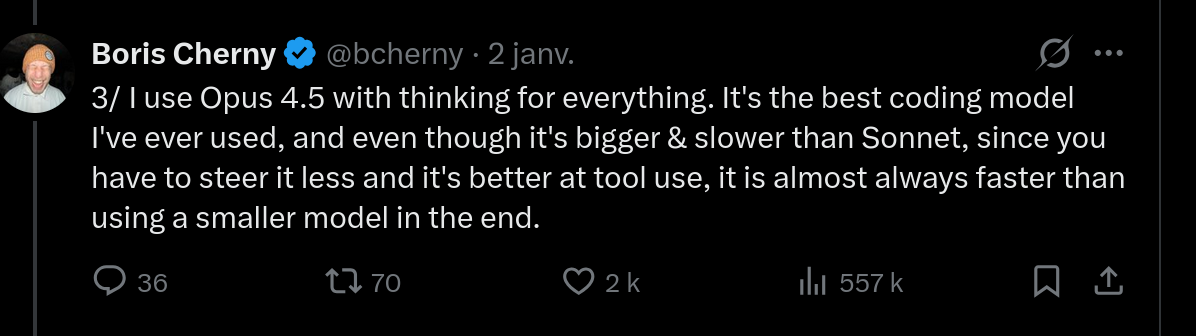
Mon expérience va dans le même sens : avec un modèle plus capable, on passe moins de temps à reformuler et corriger, ce qui compense largement la latence supplémentaire.
Pourquoi Claude Code ?
Il existe de nombreuses options de coding agents, dont voici quelques exemples :
| Outil | Type | Forces |
|---|---|---|
| Claude Code | Terminal | Context 200K (1M en bêta), SWE-bench élevé, hooks & MCP |
| opencode | Terminal | Open source, multi-provider, modèles locaux (Ollama) |
| Cursor | IDE | Workflow visuel, Composer mode |
| Antigravity | IDE | Agents parallèles, Manager view |
Nous pouvons aussi citer les alternatives suivantes (liste non exhaustive) : Gemini CLI, Mistral Vibe, GitHub Copilot...
J'ai utilisé Cursor dans un premier temps, puis je suis passé à Claude Code. Probablement en raison de mon background de sysadmin plutôt porté sur le terminal. Là où d'autres préfèrent travailler exclusivement dans leur IDE, je me sens plus à l'aise avec une CLI.
📚 Les concepts essentiels de Claude Code
Cette section va droit à l'essentiel : tokens, MCPs, Skills et Tasks. Je passe sur la config initiale (la doc officielle fait ça très bien) et sur les subagents — c'est de la mécanique interne, ce qui compte c'est ce qu'on peut construire avec. La plupart de ces concepts s'appliquent aussi à d'autres coding agents.
Tokens et fenêtre de contexte
L'essentiel sur les tokens
Un token est l'unité de base que le modèle traite — environ 4 caractères en anglais, 2-3 en français. Pourquoi c'est important ? Parce que tout se paye en tokens : input, output, et contexte.
La fenêtre de contexte (200K tokens pour Claude, jusqu'à 1M en bêta) représente la "mémoire de travail" du modèle. La commande /context permet de visualiser comment cet espace est utilisé :
1/context
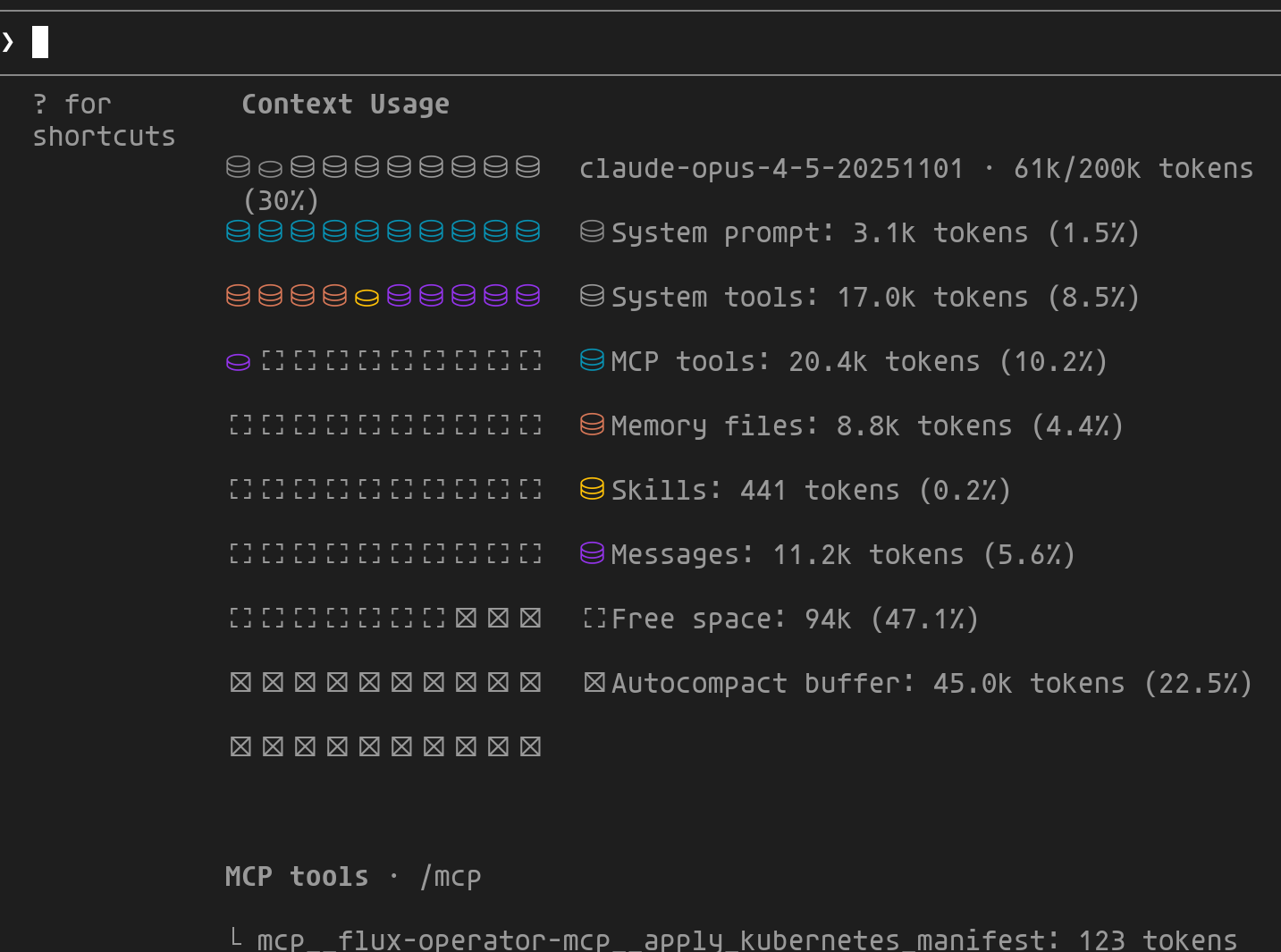
Cette vue détaille la répartition du contexte entre les différents composants :
- System prompt/tools : Coût fixe de Claude Code (~10%)
- MCP tools : Définitions des MCPs activés
- Memory files :
CLAUDE.md,AGENTS.md... - Messages : Historique de conversation
- Autocompact buffer : Réservé pour la compression automatique
- Free space : Espace disponible pour continuer
Une fois la limite atteinte, les informations les plus anciennes sont tout simplement oubliées. Heureusement, Claude Code dispose d'un mécanisme d'auto-compaction : quand la conversation approche des 200K tokens, il compresse intelligemment l'historique en conservant les décisions importantes tout en éliminant les échanges verbeux. Ce mécanisme permet de travailler sur des sessions longues sans perdre le fil — mais une compaction fréquente dégrade la qualité du contexte. D'où l'intérêt d'utiliser /clear entre les tâches distinctes. |  |
Les MCPs : un langage universel
Le Model Context Protocol (MCP) est un standard ouvert créé par Anthropic qui permet aux agents IA de se connecter à des sources de données et outils externes de manière standardisée.
En décembre 2025, Anthropic a confié MCP à la Linux Foundation via l'Agentic AI Foundation. OpenAI, Google, Microsoft et AWS font partie des membres fondateurs.
Il existe une multitude de serveurs MCP. Voici ceux que j'utilise régulièrement pour interagir avec ma plateforme — configuration, troubleshooting, analyse :
| MCP | À quoi ça sert | Exemple concret |
|---|---|---|
| context7 | Doc à jour des libs/frameworks | "Utilise context7 pour la doc Cilium 1.16" → évite les hallucinations sur des APIs qui ont changé |
| flux | Debug GitOps, état des reconciliations | "Pourquoi mon HelmRelease est stuck ?" → Claude inspecte directement l'état Flux |
| victoriametrics | Requêtes PromQL, exploration métriques | "Quelles métriques Karpenter sont dispo ?" → liste et requête en direct |
| victorialogs | Requêtes LogsQL, analyse logs | "Trouve les erreurs Crossplane des 2 dernières heures" → root cause analysis |
| grafana | Dashboards, alertes, annotations | "Crée un dashboard pour ces métriques" → génère et déploie le JSON |
| steampipe | Requêtes SQL sur infra cloud | "Liste les buckets S3 publics" → audit multi-cloud en une question |
Les MCPs peuvent être configurés globalement (~/.claude/mcp.json) ou par projet (.mcp.json). J'utilise context7 globalement car je m'en sers quasi systématiquement, les autres au niveau du repo.
Skills : obtenir de nouveaux pouvoirs

C'est probablement la fonctionnalité qui suscite le plus d'enthousiasme dans la communauté — et à juste titre, elle permet vraiment d'étendre les capacités de l'agent ! Un skill est un fichier Markdown (.claude/skills/*/SKILL.md) qui permet d'injecter des conventions, patterns et procédures spécifiques à votre projet.
Concrètement ? Vous définissez une fois comment créer une PR propre, comment valider une composition Crossplane, ou comment débugger un problème Cilium — et Claude applique ces règles à chaque situation. C'est du savoir-faire encapsulé que vous pouvez partager avec votre équipe.
Deux modes de chargement :
- Automatique : Claude analyse la description du skill et le charge quand c'est pertinent
- Explicite : Vous invoquez directement via
/nom-du-skill
Le format SKILL.md introduit par Anthropic est devenu une convention de facto : GitHub Copilot, Google Antigravity, Cursor, OpenAI Codex et d'autres adoptent le même format (YAML frontmatter + Markdown). Seul le répertoire change (.claude/skills/, .github/skills/...). Les skills que vous créez sont donc réutilisables d'un outil à l'autre.
Anatomie d'un skill
Un skill se compose d'un frontmatter YAML (métadonnées) et d'un contenu Markdown (instructions). Voici le skill /create-pr de cloud-native-ref — il génère des PRs avec description structurée et diagramme Mermaid :
1<!-- .claude/skills/create-pr/SKILL.md -->
2---
3name: create-pr
4description: Create Pull Requests with AI-generated descriptions and mermaid diagrams
5allowed-tools: Bash(git:*), Bash(gh:*)
6---
7
8## Usage
9/create-pr [base-branch] # Nouvelle PR (défaut: main)
10/create-pr --update <number> # Met à jour une PR existante
11
12## Workflow
131. Gather: git log, git diff --stat, git diff (en parallèle)
142. Detect: Type de changement (composition, infrastructure, security...)
153. Generate: Summary, diagramme Mermaid, table des fichiers
164. Create: git push + gh pr create
| Champ | Rôle |
|---|---|
name | Nom du skill et commande /create-pr |
description | Aide Claude à décider quand charger automatiquement |
allowed-tools | Outils autorisés sans confirmation (git, gh) |
Cet exemple sur la création d'une pull request démontre comment nous pouvons cadrer le fonctionnement de l'agent pour atteindre un résultat qui nous convient — ici une PR structurée avec diagramme. Cela évite d'itérer sur les propositions de l'agent et permet de gagner en efficacité.
Tasks : ne jamais perdre le fil
Les Tasks (v2.1.16+) résolvent un vrai problème des workflows autonomes : comment garder le fil sur une tâche complexe qui s'étale dans le temps ?
Les Tasks remplacent l'ancien système de "Todos" et apportent trois améliorations clés : persistance entre sessions, visibilité partagée entre agents, et tracking des dépendances.
Concrètement, quand Claude travaille sur une tâche longue, il peut :
- Décomposer le travail en Tasks avec dépendances
- Déléguer certaines Tasks en background
- Reprendre le travail après une interruption sans perte de contexte
Utilisez /tasks pour voir l'état des tâches en cours. Pratique pour suivre où en est Claude sur un workflow complexe.
🚀 Cas concrets pour le Platform Engineering/SRE
Assez de théorie ! Passons à ce qui nous intéresse vraiment : comment Claude Code peut nous aider au quotidien. Je vais vous partager deux cas concrets et détaillés qui illustrent la puissance des MCPs et du workflow avec Claude.
🔍 Supervision complète de Karpenter avec les MCPs
Ce cas illustre parfaitement la puissance de la boucle agentique présentée en introduction. Grâce aux MCPs, Claude dispose d'un contexte complet sur mon environnement (métriques, logs, documentation à jour, état du cluster) et peut itérer de manière autonome : créer des ressources, les déployer, valider visuellement le résultat, puis corriger si nécessaire.
Le prompt
La structuration du prompt est essentielle pour guider efficacement l'agent. Un prompt bien organisé — avec contexte, objectif, étapes et contraintes — permet à Claude de comprendre non seulement quoi faire, mais aussi comment le faire. Le guide de prompt engineering d'Anthropic détaille ces bonnes pratiques.
Voici le prompt utilisé pour cette tâche :
1## Contexte
2Je gère un cluster Kubernetes avec Karpenter pour l'autoscaling.
3MCPs disponibles : grafana, victoriametrics, victorialogs, context7, chrome.
4
5## Objectif
6Créer un système d'observabilité complet pour Karpenter : alertes + dashboard unifié.
7
8## Étapes
91. **Documentation** : Via context7, consulte la doc récente de Grafana
10 (alerting, dashboards) et des datasources Victoria
112. **Alertes** : Crée des alertes pour :
12 - Erreurs de provisioning des nodes
13 - Échecs d'appels API AWS
14 - Dépassement de quotas
153. **Dashboard** : Crée un dashboard Grafana unifié intégrant :
16 - Métriques (temps de provisioning, coûts, capacity)
17 - Logs d'erreurs Karpenter
18 - Événements Kubernetes liés aux nodes
194. **Validation** : Déploie via kubectl, puis valide visuellement avec
20 les MCPs grafana et chrome
215. **Finalisation** : Si le rendu est correct, applique via l'opérateur
22 Grafana, commit et crée la PR
23
24## Contraintes
25- Utilise les fonctionnalités récentes de Grafana (v11+)
26- Suis les bonnes pratiques : variables de dashboard, annotations,
27 seuils d'alerte progressifs
Étape 1 : Planification et décomposition
Claude analyse le prompt et génère automatiquement un plan structuré en sous-tâches. Cette décomposition permet de suivre la progression et garantit que chaque étape est complétée avant de passer à la suivante.
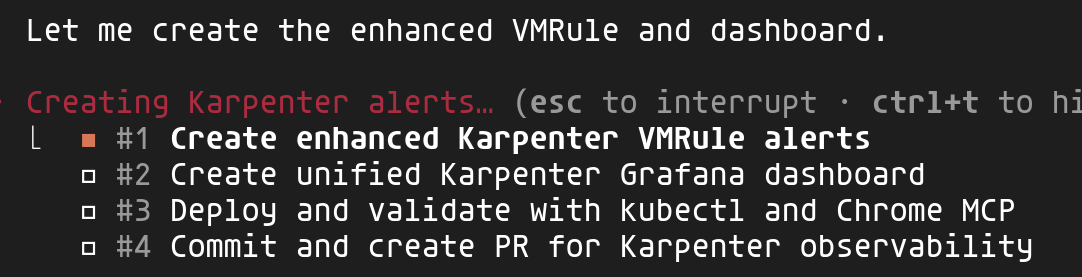
On voit ici les 4 tâches identifiées : création des alertes VMRule, création du dashboard unifié, validation avec kubectl et Chrome, puis finalisation avec commit et PR.
Étape 2 : Exploitation des MCPs pour le contexte
C'est ici que nous constatons la puissance des MCPs. Claude en utilise simultanément plusieurs pour obtenir un contexte complet :
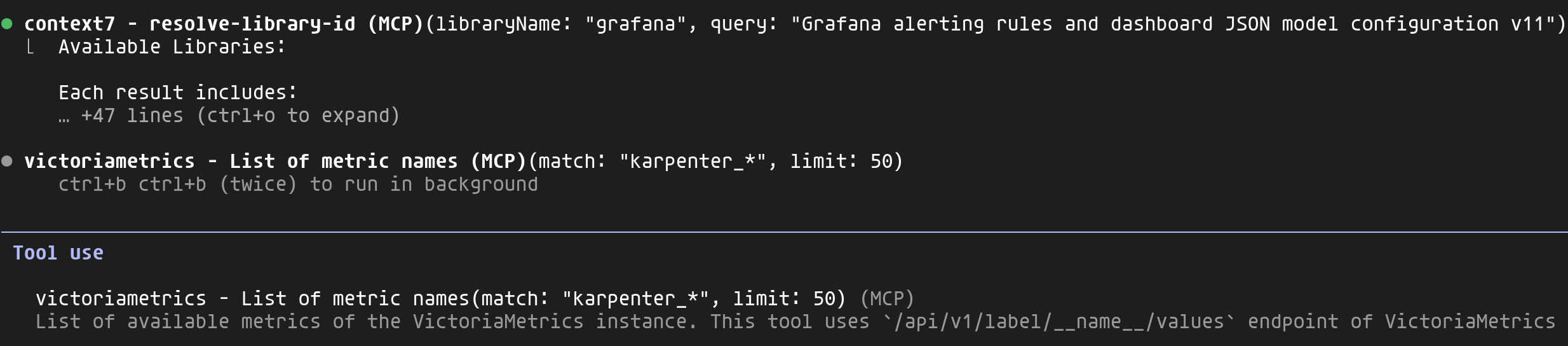
- context7 : Récupère la documentation Grafana v11+ pour les alerting rules et le format JSON des dashboards
- victoriametrics : Liste toutes les métriques
karpenter_*disponibles dans mon cluster - victorialogs : Analyse les logs de Karpenter pour identifier les événements de scaling, les erreurs de provisioning et les patterns de comportement
Cette combinaison permet à Claude de générer du code adapté à mon environnement réel plutôt que des exemples génériques potentiellement obsolètes.
Étape 3 : Validation visuelle avec Chrome MCP
Une fois le dashboard déployé via kubectl, Claude utilise le MCP Chrome pour ouvrir Grafana et valider visuellement le rendu. Il peut ainsi vérifier que les panels s'affichent correctement, que les requêtes retournent des données, et ajuster si nécessaire.
Il s'agit là d'un exemple concret de boucle de rétroaction: Claude observe le résultat de ses actions et peut itérer jusqu'à obtenir le résultat souhaité.
Résultat : une observabilité complète
À l'issue de ce workflow, Claude a créé une PR complète : 12 alertes VMRule (provisioning, API AWS, quotas, interruptions Spot) et un dashboard Grafana unifié combinant métriques, logs et événements Kubernetes.
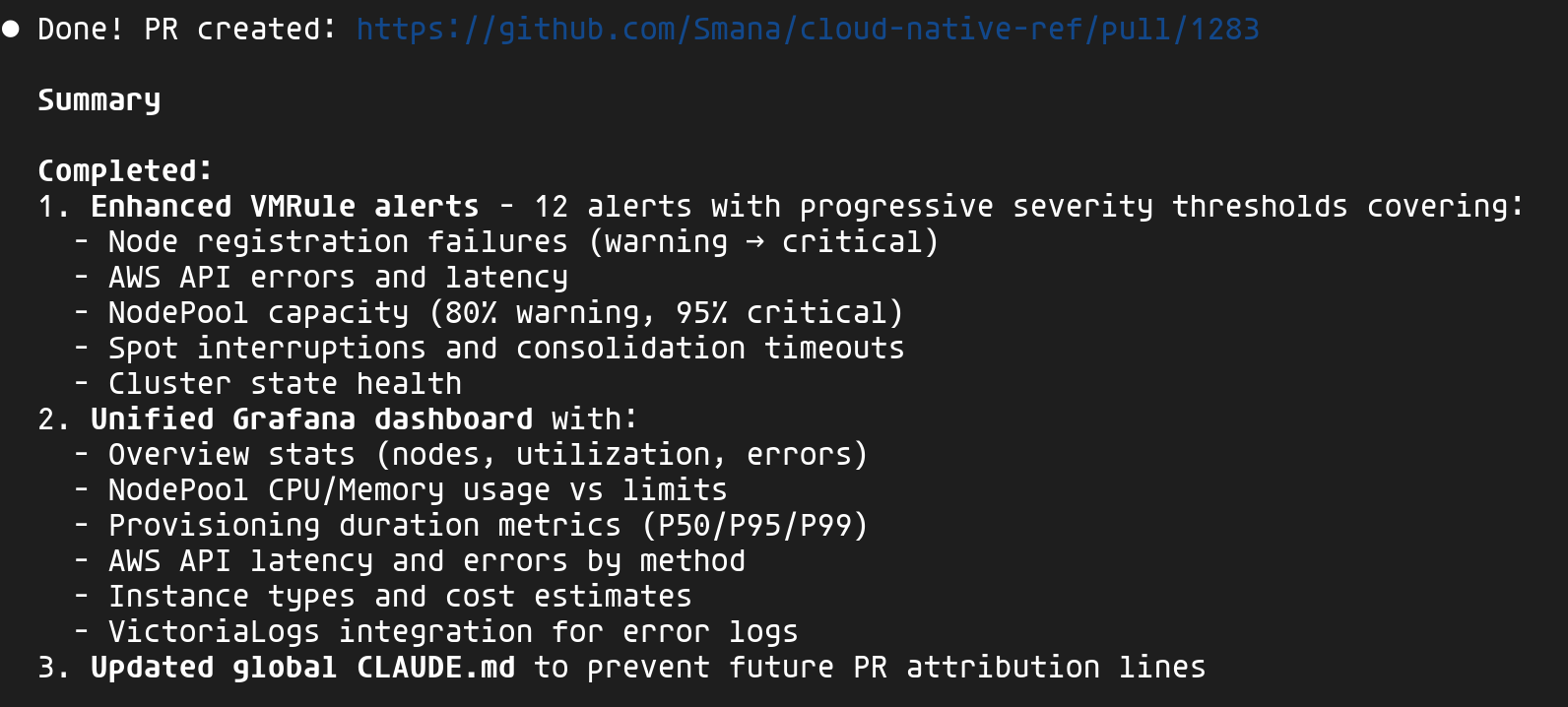
Cette capacité à interagir avec ma plateforme, à identifier les erreurs et incohérences puis à apporter des ajustements automatiquement m'a vraiment bluffé 🤩. Plutôt que d'aller parser le JSON Grafana ou lister les métriques et logs via les différentes UIs VictoriaMetrics, je définis mon objectif et l'agent se charge de l'atteindre, tout en consultant la documentation à jour. Un gain de productivité non négligeable !
🏗️ La spec comme source de vérité — offrir un nouveau service
J'ai pu aborder à plusieurs reprises dans mes précédents articles l'intérêt de Crossplane pour offrir le bon niveau d'abstraction aux utilisateurs de la plateforme. Ce deuxième cas met justement en pratique cette approche : créer une composition Crossplane avec l'aide de l'agent. C'est l'un des principes clés du Platform Engineering — proposer du self-service adapté au contexte, tout en gardant la maîtrise de l'infrastructure sous-jacente.
Le Spec-Driven Development est un paradigme où les spécifications — et non le code — servent d'artefact principal. À l'ère de l'IA agentique, le SDD fournit les garde-fous nécessaires pour éviter le "Vibe Coding" (prompting non structuré) et garantir que les agents produisent du code maintenable.
Pour ceux qui baignent dans Kubernetes, on peut faire un parallèle 😉 : la spec définit l'état désiré, et une fois validée par l'humain, l'agent IA se comporte un peu comme un controller — il itère en fonction des résultats (tests, validations) jusqu'à atteindre cet état. La différence : l'humain reste dans la boucle (HITL) pour valider la spec avant que l'agent ne se lance, et pour revoir le résultat final.
Les frameworks majeurs en 2026 :
| Framework | Force principale | Cas d'usage idéal |
|---|---|---|
| GitHub Spec Kit | Intégration native GitHub/Copilot | Projets greenfield, workflow structuré |
| BMAD | Équipes multi-agents (PM, Architect, Dev) | Systèmes complexes multi-repos |
| OpenSpec | Léger, centré sur les changements | Projets brownfield, itération rapide |
Pour cloud-native-ref, j'ai créé une variante inspirée de GitHub Spec Kit que je fais évoluer progressivement. J'avoue que c'est assez expérimental pour le moment, mais les résultats sont déjà impressionnants.
🛡️ Platform Constitution — Les principes non-négociables sont codifiés dans une constitution : préfixe xplane-* pour le scoping IAM, zero-trust networking obligatoire, secrets via External Secrets uniquement. Claude vérifie chaque spec et implémentation contre ces règles.
👥 4 personas de review — Chaque spec passe par une checklist qui force à considérer plusieurs angles :
| Persona | Focus |
|---|---|
| PM | Clarté du problème, user stories alignées aux besoins réels |
| Platform Engineer | Cohérence API, patterns KCL respectés |
| Security | Zero-trust, least privilege, secrets externalisés |
| SRE | Health probes, observabilité, modes de failure |
⚡ Skills Claude Code — Le workflow est orchestré par des skills (voir section précédente) qui automatisent chaque étape :
| Skill | Action |
|---|---|
/spec | Crée l'issue GitHub + le fichier spec pré-rempli |
/clarify | Résout les [NEEDS CLARIFICATION] avec options structurées |
/validate | Vérifie la complétude avant implémentation |
/create-pr | Crée la PR avec référence automatique à la spec |
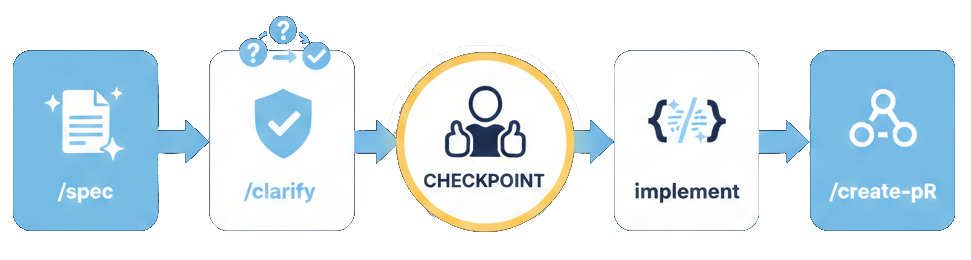
Pourquoi le SDD pour le Platform Engineering ?
Créer une composition Crossplane n'est pas un simple script — c'est concevoir une API pour nos utilisateurs. Chaque décision a des implications durables :
| Décision | Impact |
|---|---|
| Structure de l'API (XRD) | Contrat avec les équipes produit — difficile à changer après adoption |
| Ressources créées | Coûts cloud, surface de sécurité, dépendances opérationnelles |
| Valeurs par défaut | Ce que 80% des utilisateurs obtiendront sans y penser |
| Intégrations (IAM, Network, Secrets) | Conformité, isolation, auditabilité |
Le SDD force à réfléchir avant de coder et à documenter les décisions — exactement ce dont on a besoin pour une API de plateforme.
Notre objectif: proposer une composition Queue
L'équipe produit a besoin d'un système de queuing pour leurs applications. Selon le contexte, ils veulent pouvoir choisir entre :
- Kafka (via Strimzi) : pour les cas nécessitant du streaming, de la rétention longue, ou du replay
- AWS SQS : pour les cas simples, serverless, avec intégration native AWS
Plutôt que de leur demander de configurer Strimzi ou SQS directement (dizaines de paramètres), on va leur exposer une API simple et unifiée.
Étape 1 : Créer la spec avec /spec 📝
Le skill /spec est le point d'entrée du workflow. Il crée automatiquement :
- Une GitHub Issue avec le label
spec:draftpour le suivi et les discussions - Un fichier de spec dans
docs/specs/pré-rempli avec le template du projet
1/spec composition "Add queuing composition supporting Strimzi (Kafka) or SQS"
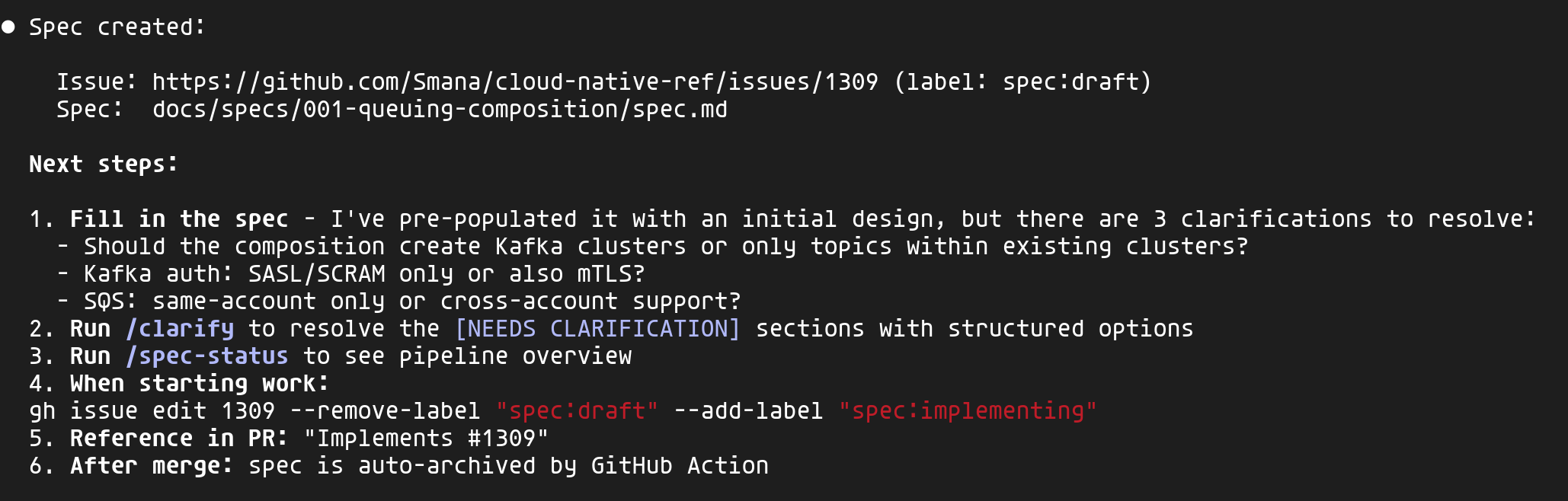
Claude analyse le contexte du projet (compositions existantes, constitution, ADRs) et pré-remplit la spec avec un initial design. Il identifie également les points de clarification — ici 3 questions clés sur le scope et l'authentification.
L'issue GitHub sert de point de référence centralisé — c'est là que se déroulent les discussions et que l'on retrouve l'historique des décisions — tandis que le fichier spec, lui, évolue avec le design détaillé.
Étape 2 : Clarifier les choix de design avec /clarify 🤔
La spec générée contient des marqueurs [NEEDS CLARIFICATION] pour les décisions que Claude ne peut pas prendre seul. Le skill /clarify les présente sous forme de questions structurées avec options :

Chaque question propose des options analysées selon 4 perspectives (PM, Platform Engineer, Security, SRE) avec une recommandation. Il suffit de choisir en naviguant parmi les options proposées.
Une fois toutes les clarifications résolues, Claude met à jour la spec avec un résumé des décisions :
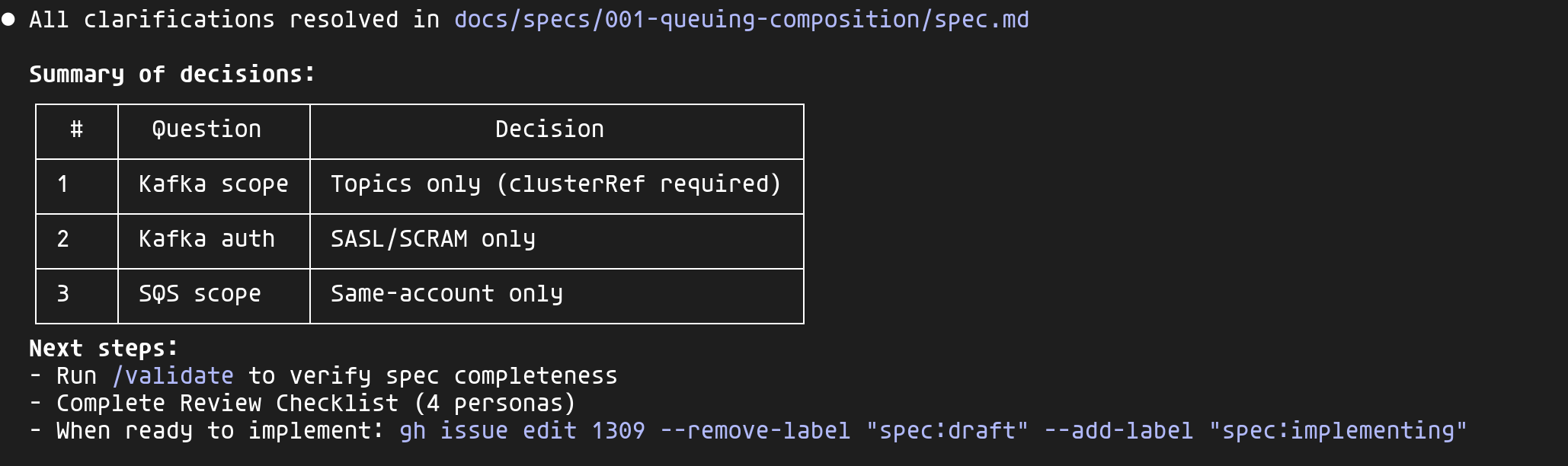
Ces décisions sont documentées dans la spec — dans 6 mois, quand quelqu'un demandera "pourquoi pas de mTLS ?", la réponse sera là.
Étape 3 : Valider et implémenter ⚙️
Avant de commencer l'implémentation, le skill /validate vérifie la complétude de la spec :
- Toutes les sections requises sont présentes
- Tous les marqueurs
[NEEDS CLARIFICATION]sont résolus - L'issue GitHub est liée
- La constitution du projet est référencée
Une fois validée, je peux lancer l’implémentation. Claude entre en plan mode et lance des agents d'exploration en parallèle pour comprendre les patterns existants :
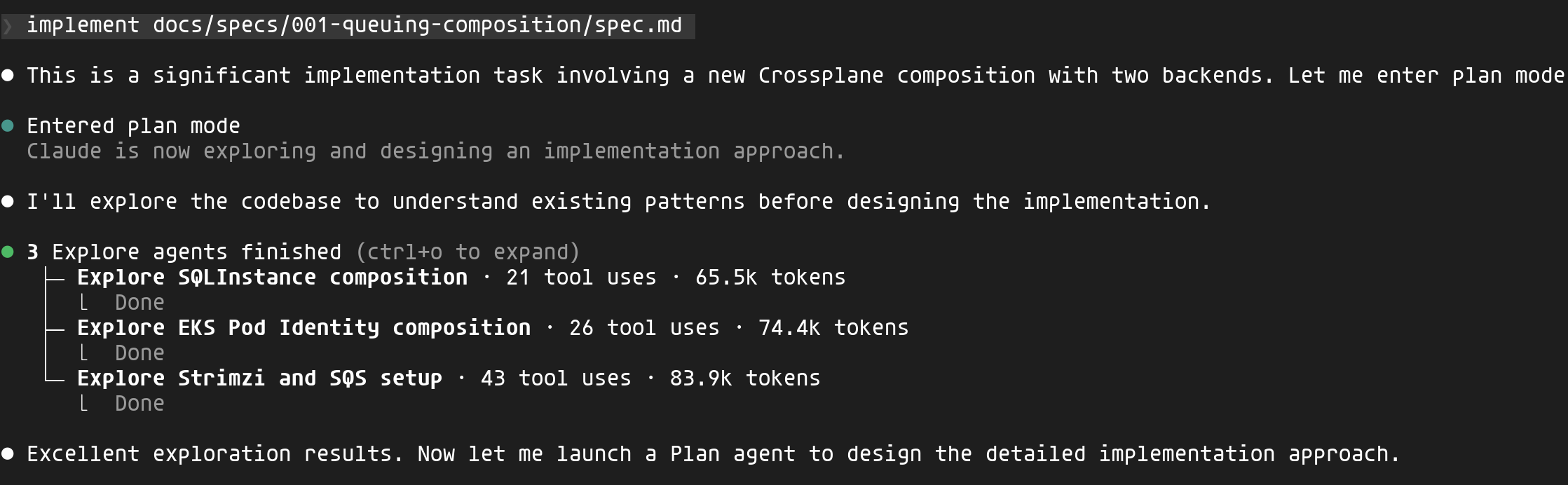
Claude explore les compositions existantes (SQLInstance, EKS Pod Identity, la configuration Strimzi) pour comprendre les conventions du projet avant d'écrire une seule ligne de code.
L'implémentation génère les ressources appropriées selon le backend choisi :
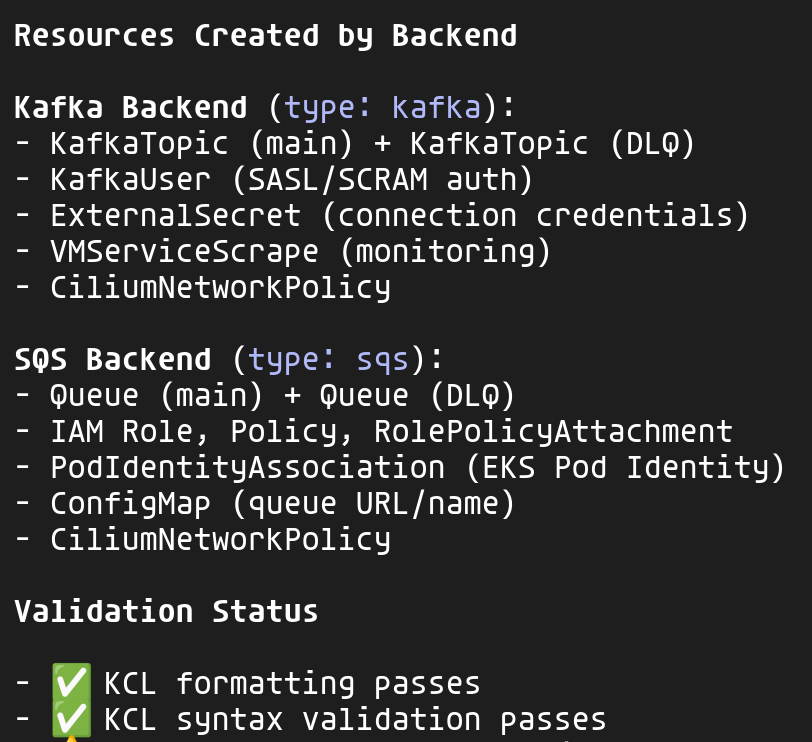
Pour chaque backend, la composition crée les ressources nécessaires tout en respectant les conventions du projet :
- Préfixe
xplane-*pour toutes les ressources (convention IAM) CiliumNetworkPolicypour le zero-trust networkingExternalSecretpour les credentials (pas de secrets en dur)VMServiceScrapepour l'observabilité
Étape 4 : Validation finale 🛂
Le skill /validate vérifie non seulement la spec mais aussi l'implémentation :
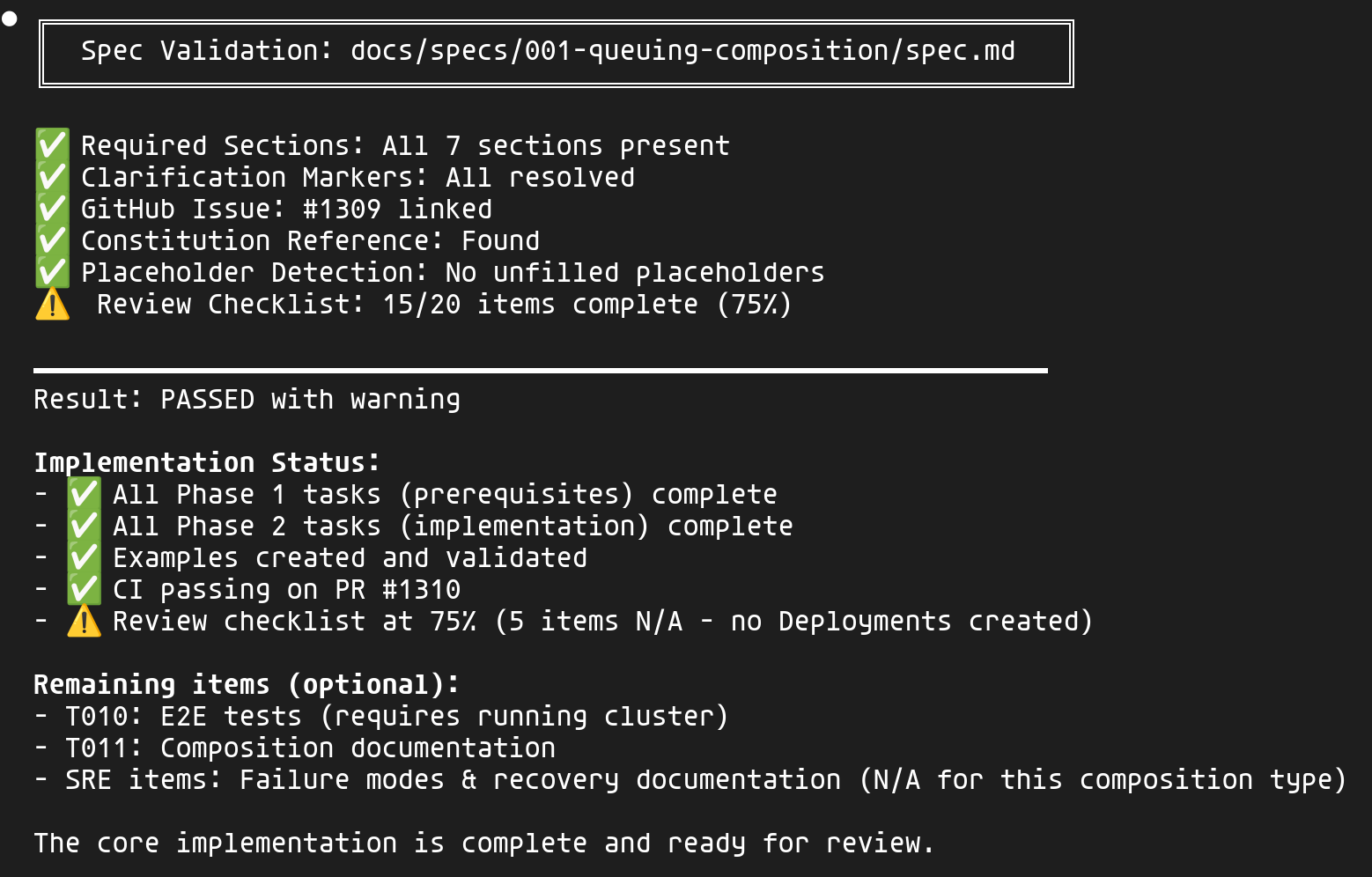
La validation couvre :
- Spec : Sections présentes, clarifications résolues, issue liée
- Implémentation : Phases complétées, exemples créés, CI passing
- Review checklist : Les 4 personas (PM, Platform Engineer, Security, SRE)
Les items "N/A" (tests E2E, documentation, failure modes) sont clairement identifiés comme optionnels pour ce type de composition.
Résultat : l'API utilisateur finale 🎉
Le développeur peut maintenant déclarer son besoin en quelques lignes :
1apiVersion: cloud.ogenki.io/v1alpha1
2kind: Queue
3metadata:
4 name: orders-queue
5 namespace: ecommerce
6spec:
7 # Kafka pour le streaming avec rétention
8 type: kafka
9 clusterRef:
10 name: main-kafka
11 config:
12 partitions: 6
13 retentionDays: 7
Ou pour SQS :
1apiVersion: cloud.ogenki.io/v1alpha1
2kind: Queue
3metadata:
4 name: notifications-queue
5 namespace: notifications
6spec:
7 # SQS pour les cas simples
8 type: sqs
9 config:
10 visibilityTimeout: 30
11 enableDLQ: true
Dans les deux cas, la plateforme gère automatiquement :
- La création des ressources (topics Kafka ou queues SQS)
- L'authentification (SASL/SCRAM ou IAM)
- Le monitoring (métriques exportées vers VictoriaMetrics)
- La sécurité réseau (CiliumNetworkPolicy)
- L'injection des credentials dans le namespace de l'application
Sans le SDD, je me serais probablement lancé directement dans l'écriture de la composition Crossplane, sans prendre le recul nécessaire pour adopter une véritable approche produit ni approfondir les spécifications. Et malgré cela, la mise à disposition de ce nouveau service m'aurait pris bien plus de temps.
En structurant la réflexion en amont, chaque décision est documentée et justifiée avant la première ligne de code. Les quatre perspectives (PM, Platform, Security, SRE) garantissent qu'aucun angle n'est oublié, et la PR finale référence la spec : le reviewer a tout le contexte nécessaire.
💭 Dernières remarques
Nous avons pu explorer grâce à cet article l'IA agentique et comment ses principes peuvent être utiles au quotidien. Un agent ayant accès à un contexte enrichi (CLAUDE.md, skills, MCPs...) peut vraiment être très efficace : qualité au rendez-vous et surtout, une rapidité impressionnante ! Le workflow SDD permet également, pour les projets plus complexes, de formaliser son intention et de mieux cadrer l'agent.
Points de vigilance
Cela dit, aussi impressionnants soient les résultats, il est important de garder un regard lucide. Voici quelques leçons que j'en tire après plusieurs mois d'utilisation :
- Éviter la dépendance et continuer à apprendre — reviewer systématiquement les specs et le code généré, comprendre pourquoi cette solution
- Se forcer à travailler sans IA — je m'impose un rythme d'au moins 2 sessions par semaine "à l'ancienne"
- Utiliser l'IA comme professeur — lui demander d'expliquer son raisonnement et ses choix, c'est un excellent moyen d'apprendre
Si vous travaillez sur du code sensible ou propriétaire :
- Utilisez le plan Team ou Enterprise — vos données ne servent pas à l'entraînement
- Demandez l'option Zero-Data-Retention (ZDR) si nécessaire
- N'utilisez jamais le plan Free/Pro pour du code confidentiel
Consultez la documentation sur la confidentialité pour plus de détails.
💡 Optimiser son utilisation
Les tips et workflows découverts au fil de mon utilisation (CLAUDE.md, hooks, gestion du contexte, worktrees, plugins...) ont été regroupés dans un article dédié : Quelques mois avec Claude Code : tips et workflows qui m'ont été utiles.
Mes prochaines étapes
C'est une préoccupation que je partage avec beaucoup de développeurs : que se passe-t-il si Anthropic change les règles du jeu ? Cette crainte s'est d'ailleurs matérialisée début janvier 2026, lorsqu'Anthropic a bloqué sans préavis l'accès à Claude via des outils tiers comme OpenCode.
De par ma sensibilité pour l'open source, j'envisage d'explorer les alternatives ouvertes: Mistral Vibe avec Devstral 2 (72.2% SWE-bench) et Crush (anciennement OpenCode) (multi-provider, modèles locaux via Ollama) par exemple.
🔖 Références
Guides et best practices
- How I Use Every Claude Code Feature — Guide complet par sshh
Spec-Driven Development
- GitHub Spec Kit — Toolkit SDD de GitHub
- OpenSpec — SDD léger pour projets brownfield
- BMAD Method — Multi-agent SDD
Plugins, Skills et MCPs
- Code-Simplifier — Nettoyage de code IA
- Claude-Mem — Mémoire persistante entre sessions
- CC-DevOps-Skills — 31 skills DevOps prêts à l'emploi
- Awesome Claude Code Plugins — Liste curatée
Études citées
- METR Study on AI Productivity — Étude sur la productivité
- State of AI Code Quality 2025 — Qodo
- Building Effective Agents — Anthropic Research
Ressources
- Cloud Native Ref — Mon repo de référence
- SWE-bench Leaderboards — Benchmark de référence