Quelques mois avec Claude Code : tips et workflows qui m'ont été utiles
Sommaire
Cet article fait suite à Agentic Coding : concepts et cas concrets, où nous avons exploré les fondamentaux de l'IA agentique — tokens, MCPs, Skills, Tasks — et deux cas pratiques détaillés. Ici, on passe à la pratique avancée : comment tirer le maximum de Claude Code au quotidien.
Comme pour tout outil qu'on adopte, c'est avec le temps qu'on affine sa façon de l'utiliser. À force d'itérer sur ma config et mes workflows, j'ai trouvé un rythme efficace avec Claude Code. Je partage ici ce qui fonctionne pour moi.
Cet article sera mis à jour au fil de mes découvertes et de l'évolution des outils. N'hésitez pas à revenir de temps en temps pour y trouver de nouveaux tips.
📜 CLAUDE.md : la mémoire persistante
Le fichier CLAUDE.md est le premier levier d'optimisation. Ce sont des instructions injectées automatiquement dans chaque conversation. Si vous n'en avez pas encore, c'est la première chose à mettre en place.
Hiérarchie de chargement
Claude Code charge les fichiers CLAUDE.md selon une hiérarchie précise :
| Emplacement | Portée | Cas d'usage |
|---|---|---|
~/.claude/CLAUDE.md | Toutes les sessions, tous les projets | Préférences globales (langue, style de commit) |
./CLAUDE.md | Projet (partagé via git) | Conventions d'équipe, commandes de build/test |
./CLAUDE.local.md | Projet (non versionné) | Préférences personnelles sur ce projet |
./sous-dossier/CLAUDE.md | Sous-arborescence | Instructions spécifiques à un module |
Les fichiers sont cumulatifs : Claude les charge tous du plus global au plus local. En cas de conflit, le plus local l'emporte.
Ce que je mets dans le mien
Voici ce que contient le CLAUDE.md de cloud-native-ref, concrètement :
- Commandes de build/test/lint — les premières lignes, pour que Claude sache comment valider son travail
- Conventions du projet — préfixe
xplane-*pour l'IAM, structure des compositions Crossplane, patterns KCL - Architecture résumée — structure des dossiers clés, pas un roman
- Erreurs fréquentes — les pièges que Claude retombe dedans si on ne le prévient pas (ex: mauvais namespace par défaut, format des labels)
Ce que je n'y mets pas : la documentation exhaustive (c'est le rôle des Skills), les exemples de code longs (je référence les fichiers existants), et les instructions évidentes que Claude connaît déjà.
Voici un extrait condensé du CLAUDE.md de cloud-native-ref pour illustrer :
1## Common Commands
2
3### Terramate Operations
4# Deploy entire platform
5terramate script run deploy
6# Preview changes across all stacks
7terramate script run preview
8# Check for configuration drift
9terramate script run drift detect
10
11## Crossplane Resources
12- **Resource naming**: All Crossplane-managed resources prefixed with `xplane-`
13
14## KCL Formatting Rules
15**CRITICAL**: Always run `kcl fmt` before committing KCL code. The CI enforces strict formatting.
16
17### Avoid Mutation Pattern (Issue #285)
18Mutating dictionaries after creation causes function-kcl to create duplicate resources.
19 # ❌ WRONG - Mutation causes DUPLICATES
20 _deployment = { ... }
21 _deployment.metadata.annotations["key"] = "value" # MUTATION!
22
23 # ✅ CORRECT - Use inline conditionals
24 _deployment = {
25 metadata.annotations = {
26 if _ready:
27 "krm.kcl.dev/ready" = "True"
28 }
29 }
On y retrouve les trois ingrédients essentiels : les commandes de build/deploy en premier (pour que Claude sache valider son travail), les conventions de nommage, et les pièges spécifiques que Claude reproduirait sans cesse si on ne le prévenait pas.
Chaque token de CLAUDE.md est chargé à chaque conversation. Un fichier trop long gaspille du contexte précieux. Visez ~500 lignes maximum et déplacez les instructions spécialisées vers des Skills qui ne se chargent qu'à la demande.
Itérer sur CLAUDE.md
Traitez CLAUDE.md comme un prompt de production : itérez dessus régulièrement. Le raccourci # permet de demander à Claude lui-même de suggérer des améliorations à votre fichier. Vous pouvez aussi utiliser le prompt improver d'Anthropic pour affiner les instructions.
🪝 Hooks : mon premier automatisme
Les hooks sont des commandes shell exécutées automatiquement en réponse à des événements Claude Code. La différence clé avec CLAUDE.md : les instructions du CLAUDE.md sont consultatives (Claude peut les ignorer), les hooks sont déterministes — ils s'exécutent systématiquement.
La notification quand Claude attend
Le premier hook que j'ai configuré — et celui que je recommande à tout le monde — c'est la notification desktop. Quand Claude termine une tâche ou attend votre validation, vous recevez une notification système accompagnée d'un son. Fini de checker le terminal toutes les 30 secondes.
Configuration dans ~/.claude/settings.json :
1{
2 "hooks": {
3 "Notification": [
4 {
5 "matcher": "",
6 "hooks": [
7 {
8 "type": "command",
9 "command": "notify-send 'Claude Code' \"$CLAUDE_NOTIFICATION\" --icon=dialog-information && paplay /usr/share/sounds/freedesktop/stereo/complete.oga"
10 }
11 ]
12 }
13 ]
14 }
15}
Sous Linux, notify-send est fourni par le paquet libnotify et paplay par pulseaudio-utils (ou pipewire-pulse). D'autres mécanismes existent pour macOS (osascript) ou d'autres environnements — consultez la doc des hooks pour les alternatives.
Les autres possibilités
Les hooks couvrent plusieurs événements (PreToolUse, PostToolUse, Notification, Stop, SessionStart) et permettent par exemple :
- Auto-format après chaque édition (ex:
gofmtsur les fichiers Go) - Protection de fichiers sensibles — un hook
PreToolUsequi bloque l'écriture dans les.env,.pem,.key(exit code 2 = action bloquée) - Audit des commandes exécutées dans un fichier de log
Je ne détaille pas ici chaque variante — la doc officielle des hooks est très bien faite. L'essentiel c'est de comprendre que les hooks sont votre filet de sécurité déterministe là où CLAUDE.md n'est qu'un conseil.
🧠 Maîtriser la fenêtre de contexte
La fenêtre de contexte (200K tokens, jusqu'à 1M en bêta) est la ressource la plus critique. Une fois saturée, les informations anciennes sont compressées et la qualité se dégrade. C'est LE sujet qui fait la différence entre un utilisateur efficace et quelqu'un qui "perd" Claude au bout de 20 minutes.
/compact avec instructions custom
La commande /compact compresse l'historique de conversation tout en préservant les décisions clés. L'astuce : vous pouvez passer des instructions de focus pour garder ce qui compte :
1/compact focus on the Crossplane composition decisions and ignore the debugging steps
C'est particulièrement utile après une longue session de debugging où 80% du contexte est du bruit (tentatives échouées, stack traces).
Stratégie /clear
La commande /clear remet le contexte à zéro. Quand l'utiliser ?
- Toujours entre deux tâches distinctes — c'est la règle la plus importante
- Quand Claude commence à halluciner ou à répéter des erreurs
- Après une longue session de debugging (le contexte est pollué par les tentatives échouées)
- Quand
/contextmontre un espace libre < 20%
J'ai pris l'habitude de commencer chaque nouvelle tâche par un /clear. Ça semble contre-intuitif (on perd le contexte), mais en pratique c'est bien plus efficace qu'un contexte pollué.
/statusline : un tableau de bord permanent
Plutôt que de lancer /context manuellement, vous pouvez configurer une barre de statut permanente en bas du terminal. La commande /statusline accepte un prompt en langage naturel pour personnaliser l'affichage. Voici ce que j'utilise :
1/statusline show current directory, git branch, and context usage percentage.
2Use ANSI colors: green for directory, cyan for git branch, yellow for context
3percentage. Use unicode separators and icons like ⎇ for branch
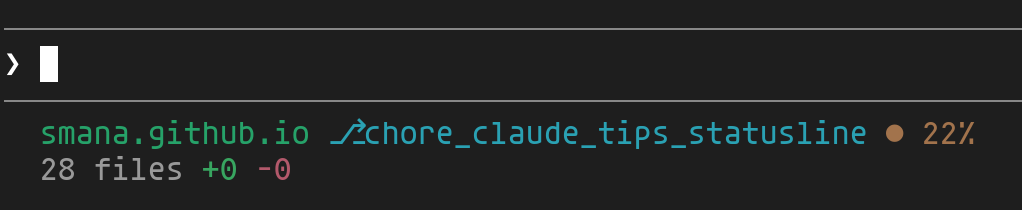
D'un coup d'oeil, on voit le répertoire courant, la branche git active et le pourcentage de contexte utilisé — trois informations essentielles pour savoir où on en est sans interrompre son flow. Particulièrement utile quand on jongle entre plusieurs worktrees ou qu'on veut anticiper un /compact.
C'est ma configuration — le prompt est libre, donc vous pouvez l'adapter pour afficher ce qui compte le plus pour vous.
Tool Search : quand les MCPs bouffent le contexte
Le problème : chaque MCP activé injecte ses définitions d'outils dans le contexte. Avec 6-7 MCPs configurés (ce qui est courant en platform engineering), ça peut représenter plus de 10% de votre fenêtre — consommé avant même de commencer à travailler.
La solution : activer le Tool Search :
1export ENABLE_TOOL_SEARCH=auto:10
Avec cette option, Claude ne charge les définitions d'outils que quand il en a besoin, plutôt que de toutes les garder en mémoire. Le 10 est le seuil (en pourcentage du contexte) à partir duquel le mécanisme s'active.
Délégation aux subagents
Pour les tâches d'exploration volumineuses (parcourir un codebase, chercher dans les logs), Claude peut déléguer à des subagents qui ont leur propre contexte isolé. Le résultat condensé est renvoyé à la session principale — économisant ainsi de précieux tokens.
En pratique, Claude le fait automatiquement quand il juge que c'est pertinent (exploration de fichiers, recherches larges). Mais vous pouvez aussi le guider explicitement : "utilise un subagent pour explorer la structure du module networking".
Quelques règles simples
/clearentre les tâches : Chaque nouvelle tâche devrait commencer par un/clear- CLAUDE.md concis : Chaque token est chargé à chaque conversation
- CLIs > MCPs : Pour les outils matures (
kubectl,git,gh...), préférez la CLI directe — les LLMs les maîtrisent parfaitement et ça évite de charger un MCP /contextpour auditer : Identifiez ce qui consomme et désactivez les MCPs non utilisés
🔄 Workflows multi-sessions
Git Worktrees : paralléliser les sessions
Plutôt que de jongler avec des branches et du stash, j'utilise les git worktrees pour travailler sur plusieurs features en parallèle avec des sessions Claude indépendantes.
1# Créer deux features en parallèle
2git worktree add ../worktrees/feature-a -b feat/feature-a
3git worktree add ../worktrees/feature-b -b feat/feature-b
4
5# Lancer deux sessions Claude distinctes
6cd ../worktrees/feature-a && claude # Terminal 1
7cd ../worktrees/feature-b && claude # Terminal 2
Chaque session a son propre contexte et sa propre mémoire — aucune interférence entre les tâches.
Contrairement à un git clone séparé :
- Historique partagé : Un seul
.git, les commits sont immédiatement visibles partout - Espace disque : ~90% d'économie (pas de duplication des objets git)
- Branches synchronisées :
git fetchdans un worktree met à jour tous les autres
Lorsque le changement est terminé (PR mergée), il suffit de retourner dans le repo principal et de faire le ménage.
1cd <path_to_main_repo>
2git worktree remove ../worktrees/feature-a
3git branch -d feat/feature-a # après merge de la PR
Commandes utiles :
1git worktree list # Voir tous les worktrees actifs
2git worktree prune # Nettoyer les références orphelines
Pattern Writer/Reviewer
Un pattern que j'utilise de plus en plus consiste à lancer deux sessions en parallèle :
| Session | Rôle | Prompt |
|---|---|---|
| Writer | Implémente le code | "Implémente la feature X selon la spec" |
| Reviewer | Review le code | "Review les changements sur la branche feat/X, vérifie la sécurité et les edge cases" |
Le reviewer travaille sur le même repo (via worktree ou en lecture seule) et fournit un feedback indépendant, sans le biais de l'auteur. C'est particulièrement efficace pour les changements d'infrastructure où une erreur peut coûter cher.
Fan-out avec -p
Le flag -p (prompt non-interactif) permet d'exécuter Claude en mode headless et de paralléliser les tâches :
1# Lancer 3 tâches en parallèle
2claude -p "Ajoute des tests unitaires pour le module auth" &
3claude -p "Documente l'API REST du service orders" &
4claude -p "Refactore le module billing pour utiliser le nouveau SDK" &
5wait
Chaque instance a son propre contexte. C'est idéal pour les tâches indépendantes qui ne nécessitent pas d'interaction.
Teams : faire collaborer des agents
L'approche -p fonctionne très bien pour des tâches indépendantes, mais parfois on a besoin d'agents qui communiquent entre eux. C'est le rôle des teams — Claude lance plusieurs agents qui partagent une liste de tâches, échangent des messages, et peuvent attendre les résultats des autres. Pour moi, c'est la killer feature d'Opus 4.6 : on parallélise le travail, on gagne en performance, et chaque agent a son propre contexte au lieu de tout entasser dans une seule session.
Les agent teams sont encore en research preview. Pour les activer, ajoutez ceci dans votre settings.json :
1{
2 "env": {
3 "CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "1"
4 },
5 "teammateMode": "tmux"
6}
Le teammateMode contrôle comment les agents sont affichés : "tmux" ouvre chaque agent dans un pane séparé (nécessite tmux), "in-process" les fait tourner dans le même terminal, et "auto" (par défaut) choisit automatiquement selon votre environnement.
Pour illustrer le principe, j'ai testé ça sur un cas volontairement simple : analyser une composition Crossplane. L'exemple est basique, mais les cas d'usage réels sont nombreux — troubleshooting d'un incident en parallélisant l'analyse des logs, métriques et configs, création d'un nouveau service en répartissant code, tests et documentation entre agents, ou encore audit de sécurité multi-composants. Ici, plutôt que de lire le code, puis les exemples, puis rédiger une synthèse — le tout séquentiellement dans la même session — j'ai simplement demandé :
1Create a team of 3 agents to analyze the Crossplane App composition.
21. code-reader: Read main.k and summarize what resources it creates
32. example-reader: Read all example files and list the configuration options
43. doc-writer: Wait for the other two, then write a combined summary
Voici ce que ça donne en pratique : trois panes tmux côte à côte — les deux readers analysent le code et les exemples en parallèle, pendant que le doc-writer attend leur sortie avant de produire la synthèse finale.
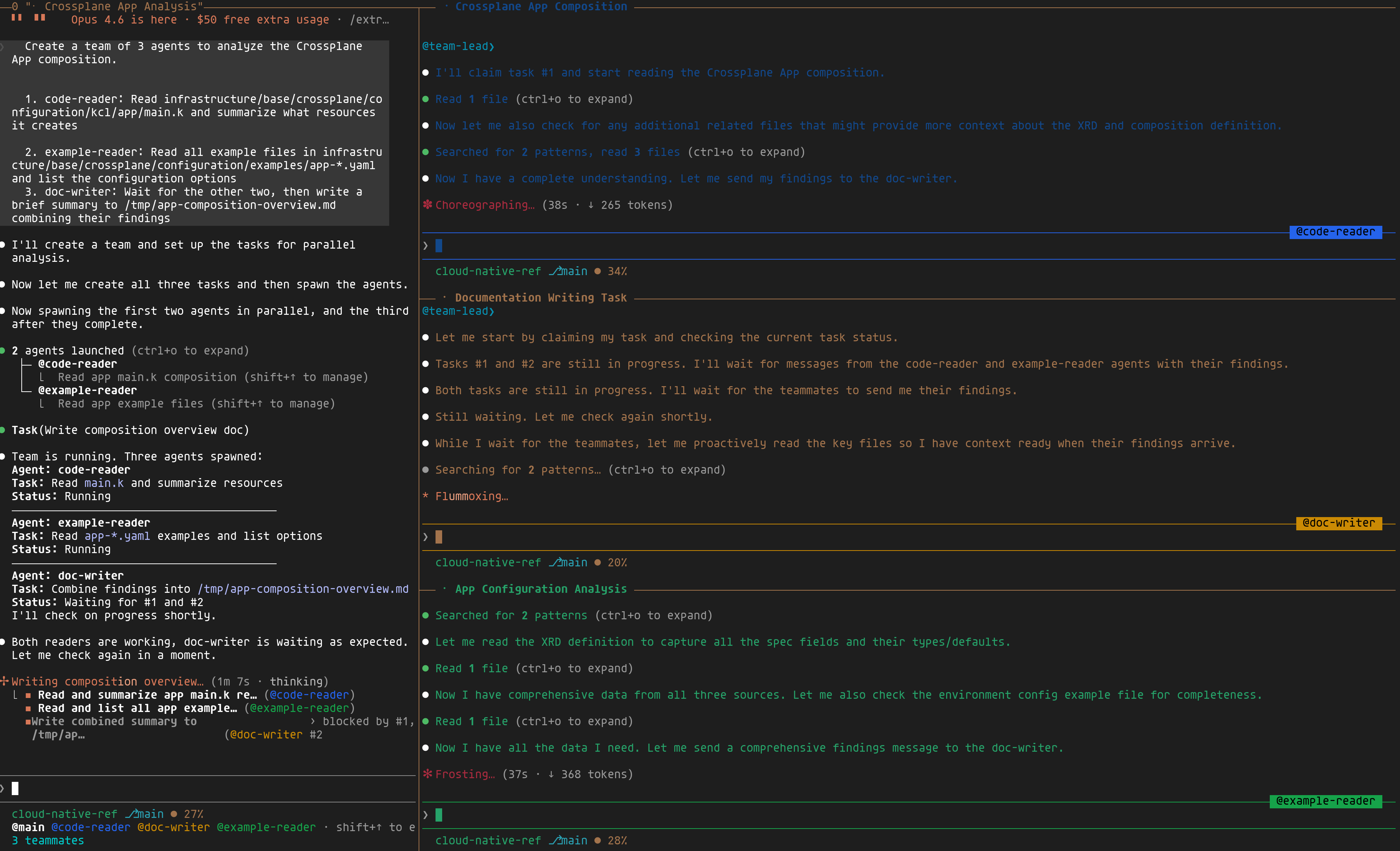
Les teams brillent quand vous avez du travail indépendant qui doit converger — lire/analyser/synthétiser, construire/tester/documenter, ce genre de chose. Pour des tâches purement séquentielles, une session unique avec /clear entre les étapes reste plus simple.
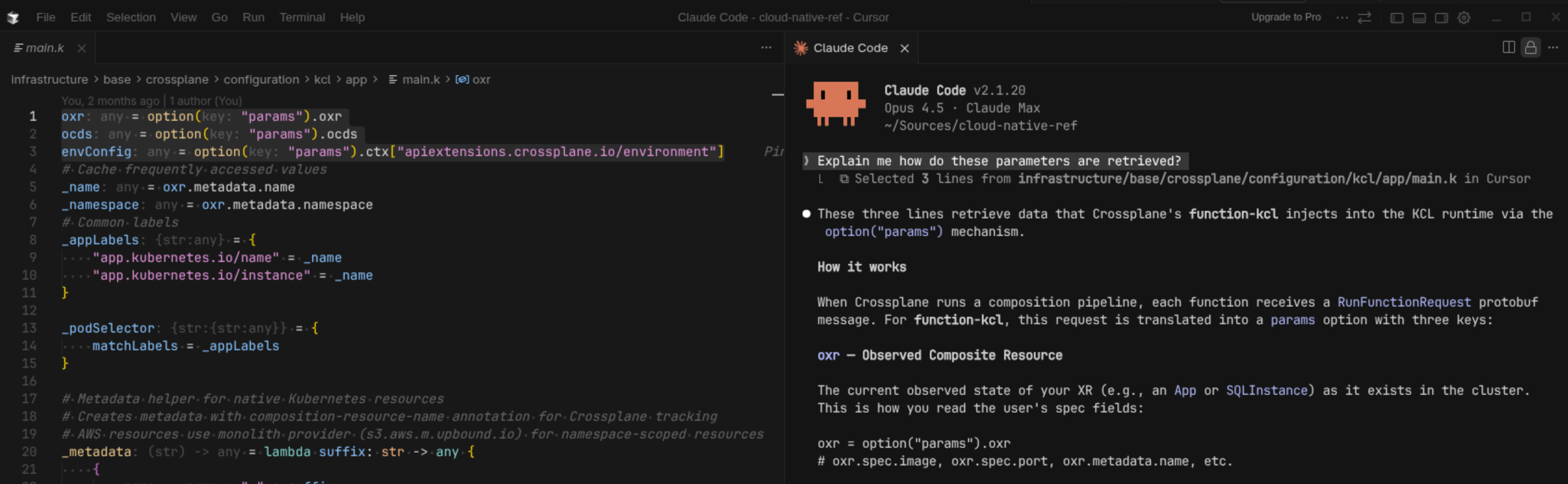
🖥️ Workflow hybride IDE + Claude Code
En pratique, j'alterne entre deux modes : parfois en terminal pur — vieille habitude — et parfois en mode hybride avec Cursor pour l'édition et Claude Code dans le terminal. Le workflow hybride est clairement plus confortable, et je m'y mets de plus en plus.
| Besoin | Outil | Pourquoi |
|---|---|---|
| Édition rapide, autocomplete | Cursor | Latence minimale, vous restez dans le flow |
| Refactoring, debugging multi-fichiers | Claude Code | Raisonnement profond, boucles autonomes |
Ce que j'apprécie dans le mode hybride : Claude modifie via le terminal, et je valide les diffs dans l'interface Cursor — bien plus lisible que git diff. Les changements apparaissent en temps réel dans l'éditeur, ce qui permet de suivre ce que Claude fait et d'intervenir rapidement si besoin.
🔌 Plugins
Claude Code dispose d'un écosystème de plugins qui étendent ses capacités. Voici les deux que j'utilise au quotidien :
Code-Simplifier : nettoyer le code généré
Le plugin code-simplifier est développé par Anthropic et utilisé en interne par l'équipe Claude Code. Il nettoie automatiquement le code généré par l'IA tout en préservant la fonctionnalité.
J'ai découvert ce plugin récemment et je compte m'efforcer de l'utiliser systématiquement avant de créer une PR après une session intensive. Il tourne sur Opus et devrait aider à réduire la dette technique introduite par le code IA — code dupliqué, structures inutilement complexes, style incohérent.
Claude-Mem : mémoire persistante entre sessions
Le plugin claude-mem capture automatiquement le contexte de vos sessions et le réinjecte dans les sessions futures. Plus besoin de réexpliquer votre projet à chaque nouvelle conversation.
Ses deux atouts principaux :
- Recherche sémantique : retrouver facilement une information d'une session passée via le skill
mem-search - Optimisation de la consommation de tokens : un workflow 3-layer qui réduit significativement l'usage (~10x d'économie)
Exemples d'utilisation :
- "Cherche dans mes sessions quand j'ai debuggé Karpenter"
- "Retrouve ce que j'ai appris sur OpenBao PKI la semaine dernière"
- "Regarde mon travail précédent sur la composition App"
Claude-mem stocke localement les données de session. Pour les projets sensibles, utilisez les tags <private> pour exclure des informations de la capture.
⚠️ Anti-patterns
Voici les pièges dans lesquels je suis tombé — et que j'ai appris à éviter :
| Anti-pattern | Symptôme | Solution |
|---|---|---|
| Kitchen sink session | Mélanger debugging, feature, refactoring dans une même session | /clear entre chaque tâche distincte |
| Spirale de corrections | Claude corrige un bug, en crée un autre, boucle sans fin | Arrêter, /clear, reformuler avec plus de contexte |
| CLAUDE.md trop gros | Context consommé dès le départ, réponses dégradées | Viser ~500 lignes, déplacer le reste vers les Skills |
| Trust-then-verify gap | Accepter le code sans review, découvrir les bugs en prod | Toujours lire le diff avant de commit |
| Exploration infinie | Claude parcourt tout le codebase au lieu d'agir | Donner des fichiers/chemins précis dans le prompt |
La spirale de corrections est de loin le plus dangereux. Exemple vécu : Claude devait ajouter une CiliumNetworkPolicy à une composition Crossplane. Premier essai, mauvais sélecteur d'endpoint. Il corrige, mais casse le format KCL. Il re-corrige le format, mais revient au mauvais sélecteur initial. Au bout de 5 itérations et ~40K tokens consommés, j'ai fait /clear et reformulé en 3 lignes en précisant le namespace cible et un exemple de policy existante. Résultat correct du premier coup. La leçon : quand Claude boucle après 2-3 tentatives, c'est le signe qu'il lui manque du contexte, pas de la persévérance. Mieux vaut couper et reformuler que de le laisser tourner.
🏁 Conclusion
Au fil du temps, je me sens de plus en plus à l'aise avec Claude Code, et le gain de productivité est réel. Mais il s'accompagne d'une crainte que je n'arrive pas à évacuer complètement : celle de perdre le contrôle — sur le code produit, sur les décisions prises, sur la compréhension de ce qui tourne en production.
Ces interrogations, mais aussi les méthodes qui me permettent d'être le maître de la situation, je les aborde dans le premier article de cette série. Si vous voulez revenir aux fondamentaux ou comprendre d'où viennent ces réflexions, je vous le conseille vivement : Agentic Coding : concepts et cas concrets.
🔖 Références
Documentation officielle
- Claude Code Documentation — Guide officiel
- Hooks Documentation — Configuration des hooks
Guides communautaires
- How I Use Every Claude Code Feature — Guide complet par sshh
- CC-DevOps-Skills — 31 skills DevOps
Plugins et outils
- Code-Simplifier — Nettoyage de code IA (Anthropic)
- Claude-Mem — Mémoire persistante entre sessions
Article précédent
- Agentic Coding : concepts et cas concrets — Partie 1 de la série Agentic AI