Une solution complète et performante pour gérer vos métriques avec les opérateurs VictoriaMetrics et Grafana!
Sommaire
Une fois que notre application est déployée, il est primordial de disposer d'indicateurs permettant d'identifier d'éventuels problèmes ainsi que suivre les évolutions de performance. Parmi ces éléments, les métriques et les logs jouent un rôle essentiel en fournissant des informations précieuses sur le fonctionnement de l'application. En complément, il est souvent utile de mettre en place un tracing détaillé pour suivre précisément toutes les actions réalisées par l'application.
Dans cette série d'articles, nous allons explorer les différents aspects liés à la supervision applicative. L'objectif étant d'analyser en détail l'état de nos applications, afin d'améliorer leur disponibilité et leurs performances, tout en garantissant une expérience utilisateur optimale.
Ce premier volet est consacré à la collecte et la visualisation des métriques. Nous allons déployer une solution performante et évolutive pour acheminer ces métriques vers un système de stockage fiable et pérenne. Puis nous allons voir comment les visualiser afin de les analyser.
❓ Qu'est ce qu'une métrique
Definition
Avant de collecter cette dite "métrique", penchons-nous d'abord sur sa définition et ses spécificités:Une métrique est une donnée mesurable qui permet de suivre l'état et les performances d'une application. Ces données sont généralement des chiffres collectés à intervals réguliers, on peut citer par exemple le nombre de requêtes, la quantité de mémoire ou le taux d'erreurs.
Et quand on s'intéresse au domaine de la supervision, il est difficile de passer à coté de Prometheus. Ce projet a notamment permis le l'émergence d'un standard qui définit la manière dont on expose des métriques appelé OpenMetrics dont voici le format.

Time Series: Une
time seriesunique est la combinaison du nom de la métrique ainsi que ses labels, par conséquentrequest_total{code="200"}etrequest_total{code="500"}sont bien 2 time series distinctes.Labels: On peut associer des
labelsà une métrique afin de la caractériser plus précisément. Ils sont ajoutées à la suite du nom de la métrique en utilisant des accolades. Bien qu'ils soient optionnels, nous les retrouverons très souvent, notamment dans sur un cluster Kubernetes (pod, namespace...).Value: La
valuereprésente une donnée numérique recueillie à un moment donné pour une time series spécifique. Selon le type de métrique, il s'agit d'une valeur qui peut être mesurée ou comptée afin de suivre l'évolution d'un indicateur dans le temps.Timestamp: Indique quand la donnée a été collectée (format epoch à la milliseconde). S'il n'est pas présent, Il est ajouté au moment où la métrique est récupérée.
Cette ligne complète représente ce que l'on appelle un raw sample.
Plus il y a de labels, plus les combinaisons possibles augmentent, et par conséquent, le nombre de timeseries. Le nombre total de combinaisons est appelé cardinalité. Une cardinalité élevée peut avoir un impact significatif sur les performances, notamment en termes de consommation de mémoire et de ressources de stockage.
Une cardinalité élevée se produit également lorsque de nouvelles métriques sont créées fréquemment. Ce phénomène, appelé churn rate, indique le rythme auquel des métriques apparaissent puis disparaissent dans un système. Dans le contexte de Kubernetes, où des pods sont régulièrement créés et supprimés, ce churn rate peut contribuer à l'augmentation rapide de la cardinalité.
La collecte en bref
Maintenant que l'on sait ce qu'est une métrique, voyons comment elles sont collectées. La plupart des solutions modernes exposent un endpoint qui permet de "scraper" les métriques, c'est-à-dire de les interroger à intervalle régulier. Par exemple, grâce au SDK Prometheus, disponible dans la plupart des langages de programmation, il est facile d'intégrer cette collecte dans nos applications.
Il est d'ailleurs important de souligner que Prometheus utilise, en règle générale, un modèle de collecte en mode "Pull", où le serveur interroge périodiquement les services pour récupérer les métriques via ces endpoints exposés. Cette approche permet de mieux contrôler la fréquence de collecte des données et d'éviter de surcharger les systèmes. On distinguera donc le mode "Push" où ce sont les applications qui envoient directement les informations.
Illustrons cela concrètement avec un serveur web Nginx. Ce serveur est installé à partir du chart Helm en activant le support de Prometheus. Ici le paramètre metrics.enabled=true permet d'ajouter un chemin qui expose les métriques.
1helm install ogenki-nginx bitnami/nginx --set metrics.enabled=true
Ainsi, nous pouvons par exemple récupérer via un simple appel http un nombre de métriques important
1kubectl port-forward svc/ogenki-nginx metrics &
2Forwarding from 127.0.0.1:9113 -> 9113
3
4curl -s localhost:9113/metrics
5...
6# TYPE promhttp_metric_handler_requests_total counter
7promhttp_metric_handler_requests_total{code="200"} 257
8...
La commande curl était juste un exemple, La collecte est, en effet réalisée par un système dont la responsabilité est de stocker ces données pour pouvoir ensuite les exploiter et les analyser.
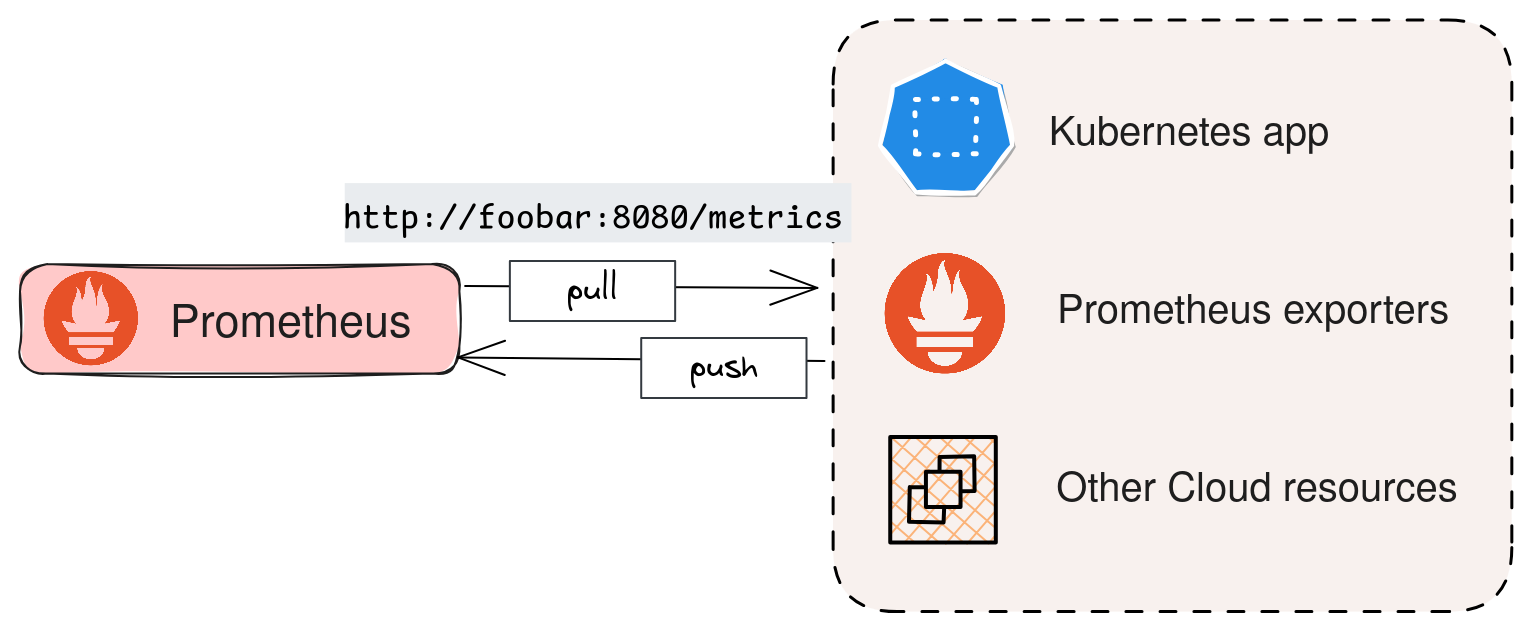
ℹ️ Quand on utilise Prometheus, un composant supplémentaire est nécessaire pour pouvoir pousser des métriques depuis les applications: PushGateway.
Dans cet article, j'ai choisi de vous faire découvrir VictoriaMetrics.
✨ VictoriaMetrics: Un héritier de Prometheus
Tout comme Prometheus, VictoriaMetrics est une base de données Time Series (TSDB). Celles-cis sont conçues pour suivre et stocker des événements qui évoluent au fil du temps. Même si VictoriaMetrics est apparue quelques années après Prometheus, elles partagent pas mal de points communs : ce sont toutes deux des bases de données open-source sous licence Apache 2.0, dédiées au traitement des time series. VictoriaMetrics reste entièrement compatible avec Prometheus, en utilisant le même format de métriques, OpenMetrics, et un support total du langage de requêtes PromQL.
Ces deux projets sont d’ailleurs très actifs, avec des communautés dynamiques et des contributions régulières venant de nombreuses entreprises comme on peut le voir ici.
Explorons maintenant les principales différences et les raisons qui pourraient pousser à choisir VictoriaMetrics :
Stockage et compression efficace : C'est probablement l'un des arguments majeurs, surtout quand on gère un volume important de données ou qu'on souhaite les conserver à long terme. Avec Prometheus, il faut ajouter un composant supplémentaire, comme Thanos, pour cela. VictoriaMetrics, en revanche, dispose d'un moteur de stockage optimisé qui regroupe et optimise les données avant de les écrire sur disque. De plus, il utilise des algorithmes de compression très puissants, offrant une utilisation de l'espace disque bien plus efficace que Prometheus.
Empreinte mémoire : VictoriaMetrics consommerait jusqu'à 7 fois moins de mémoire qu'une solution basée sur Prometheus. Cela dit, les benchmarks disponibles en ligne commencent à dater, et Prometheus a bénéficié de nombreuses optimisations de mémoire.
MetricsQL : VictoriaMetrics étend le langage PromQL avec de nouvelles fonctions. Ce language est aussi conçu pour être plus performant, notamment sur un large dataset.
Architecture modulaire: VictoriaMetrics peut être déployé en 2 modes: "Single" ou "Cluster". Selon le besoin on pourra aller bien plus loin: On verra cela dans la suite de l'article.
Et bien d'autres...: Les arguments ci-dessus sont ceux que j'ai retenu mais il y en a d'autres. VictoriaMetrics peut aussi être utilisé en mode Push, configuré pour du multitenant et d'autres fonctions que l'on retrouvera dans la version entreprise.
Sur le site de VictoriaMetrics, on trouve de nombreux témoignages et retours d'expérience d'entreprises ayant migré depuis d'autres systèmes (comme Thanos, InfluxDB, etc.). Certains exemples sont particulièrement instructifs, notamment ceux de Roblox, Razorpay ou Criteo, qui gèrent un volume très important de métriques.
🔎 Une architecture modulaire et scalable
 | Le reste de cet article est issu d'un ensemble de configurations que vous pouvez retrouver dans le repository Cloud Native Ref.Il y est fait usage de nombreux opérateurs et notamment ceux pour VictoriaMetrics et pour Grafana. L'ambition de ce projet est de pouvoir démarrer rapidement une plateforme complète qui applique les bonnes pratiques en terme d'automatisation, de supervision, de sécurité etc.Les commentaires et contributions sont les bienvenues 🙏 |
VictoriaMetrics peut être déployé de différentes manières: Le mode par défaut est appelé Single et, comme son nom l'indique, il s'agit de déployer une instance unique qui gère la lecture, l'écriture et le stockage. Il est d'ailleurs recommandé de commencer par celui-ci car il est optimisé et répond à la plupart des cas d'usage comme le précise ce paragraphe.
Le mode Single
La méthode de déploiement choisie dans cet article fait usage du chart Helm victoria-metrics-k8s-stack qui configure de nombreuses ressources (VictoriaMetrics, Grafana, Alertmanager, quelques dashboards...). Voici un extrait de configuration Flux pour un mode Single
observability/base/victoria-metrics-k8s-stack/helmrelease-vmsingle.yaml
1apiVersion: helm.toolkit.fluxcd.io/v2
2kind: HelmRelease
3metadata:
4 name: victoria-metrics-k8s-stack
5 namespace: observability
6spec:
7 releaseName: victoria-metrics-k8s-stack
8 chart:
9 spec:
10 chart: victoria-metrics-k8s-stack
11 sourceRef:
12 kind: HelmRepository
13 name: victoria-metrics
14 namespace: observability
15 version: "0.25.15"
16...
17 values:
18 vmsingle:
19 spec:
20 retentionPeriod: "1d" # Minimal retention, for tests only
21 replicaCount: 1
22 storage:
23 accessModes:
24 - ReadWriteOnce
25 resources:
26 requests:
27 storage: 10Gi
28 extraArgs:
29 maxLabelsPerTimeseries: "50"
Lorsque l'ensemble des manifests Kubernetes sont appliqués, on obtient l'architecture suivante:
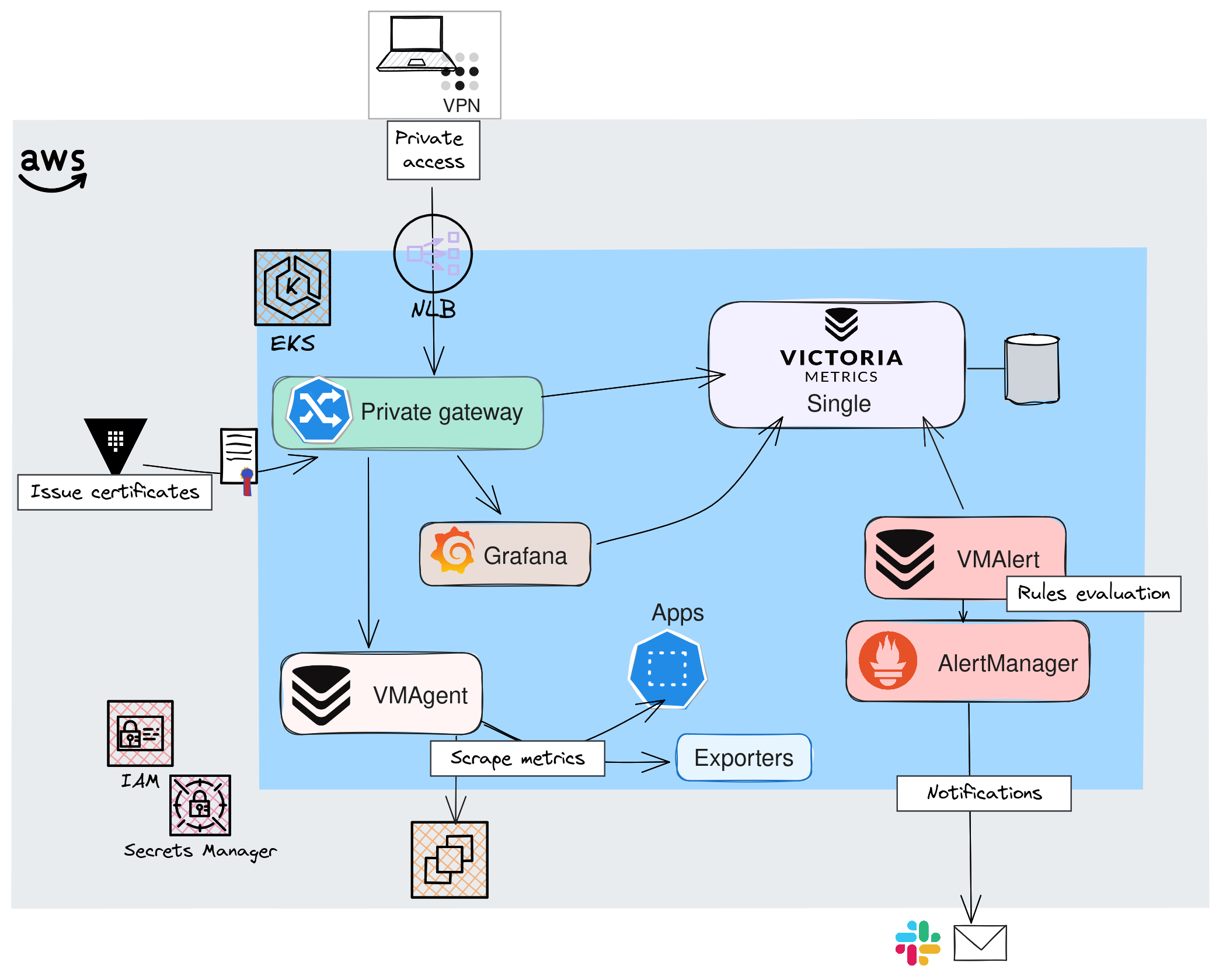
🔒 Accès privé: Même si cela ne fait pas vraiment partie des composants liés à la collecte des métriques, j'ai souhaité mettre en avant la façon dont on accède aux différentes interfaces. J'ai en effet choisi de capitaliser sur Gateway API, que j'utilise depuis quelques temps et qui a fait l'objet de précédents articles. Une alternative serait d'utiliser un composant de VictoriaMetrics, VMAuth, qui peut servir de proxy pour l'autorisation et le routage des accès mais Je n'ai pas retenu cette option pour le moment.
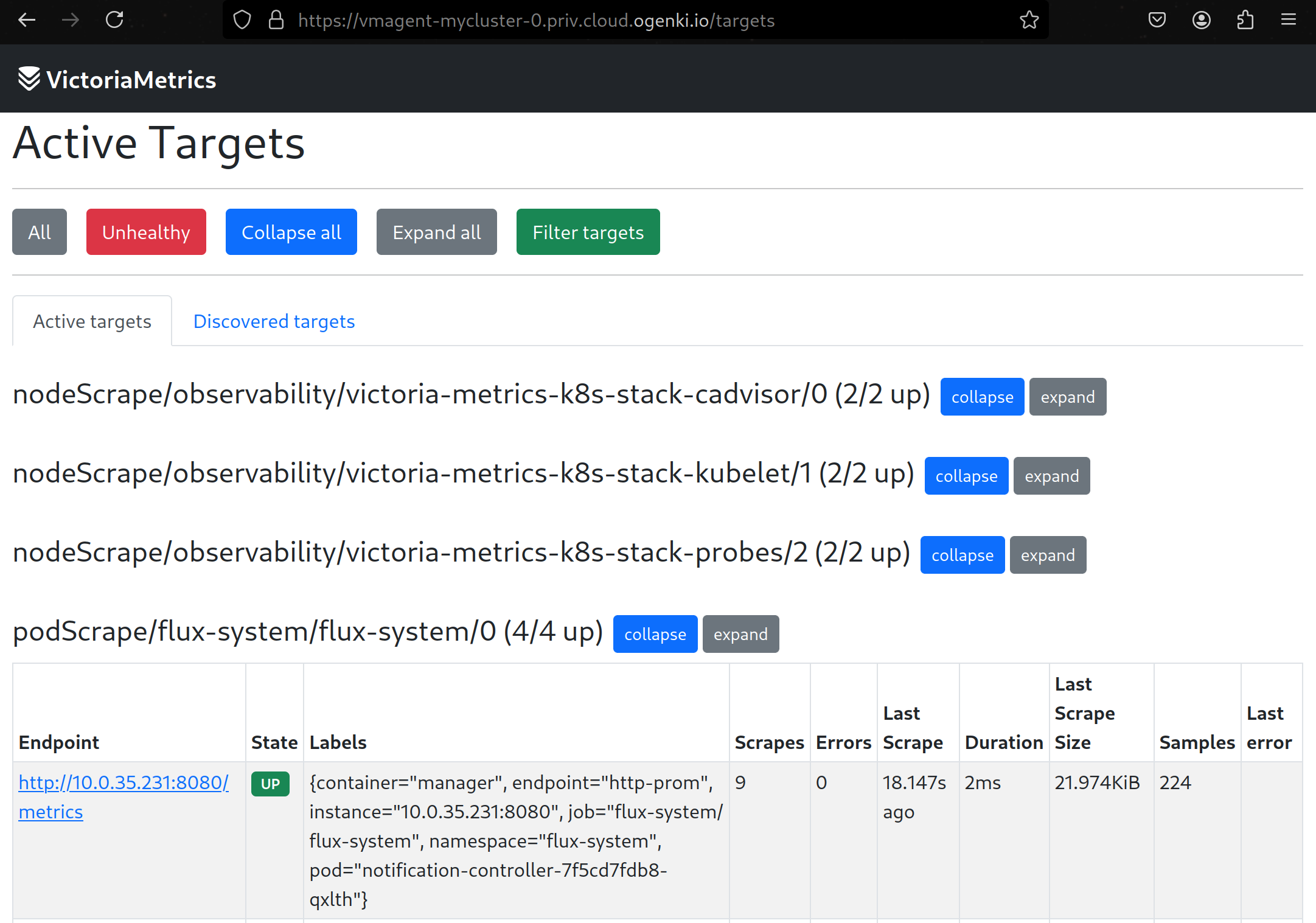
👷 VMAgent: Un agent très léger, dont la fonction principale est de récupérer les métriques et de les acheminer vers une base de données compatible avec Prometheus. Par ailleurs, cet agent peut appliquer des filtres ou des transformations aux métriques avant de les transmettre. En cas d'indisponibilité de la destination ou en cas de manque de ressources, il peut mettre en cache les données sur disque. VMAgent dispose aussi d'une interface Web permettant de lister les "Targets" (Services qui sont scrapés)
🔥 VMAlert & VMAlertManager: Ce sont les composants chargés de notifier en cas de problèmes, d'anomalies. Je ne vais volontairement pas approfondir le sujet car cela fera l'objet d'un future acticle.
⚙️ VMsingle: Il s'agit de la base de données VictoriaMetrics déployée sous forme d'un pod unique qui prend en charge l'ensemble des opérations (lecture, écriture et persistence des données).
Lorsque tous les pods sont démarrés, on peut accéder à l'interface principale de VictoriaMetrics: VMUI. Elle permet de visualiser un grand nombre d'informations: Évidemment nous pourrons parcourir les métriques scrapées, les requêtes les plus utilisées, les statistiques relatives à la cardinalité et bien d'autres.
La Haute disponibilité
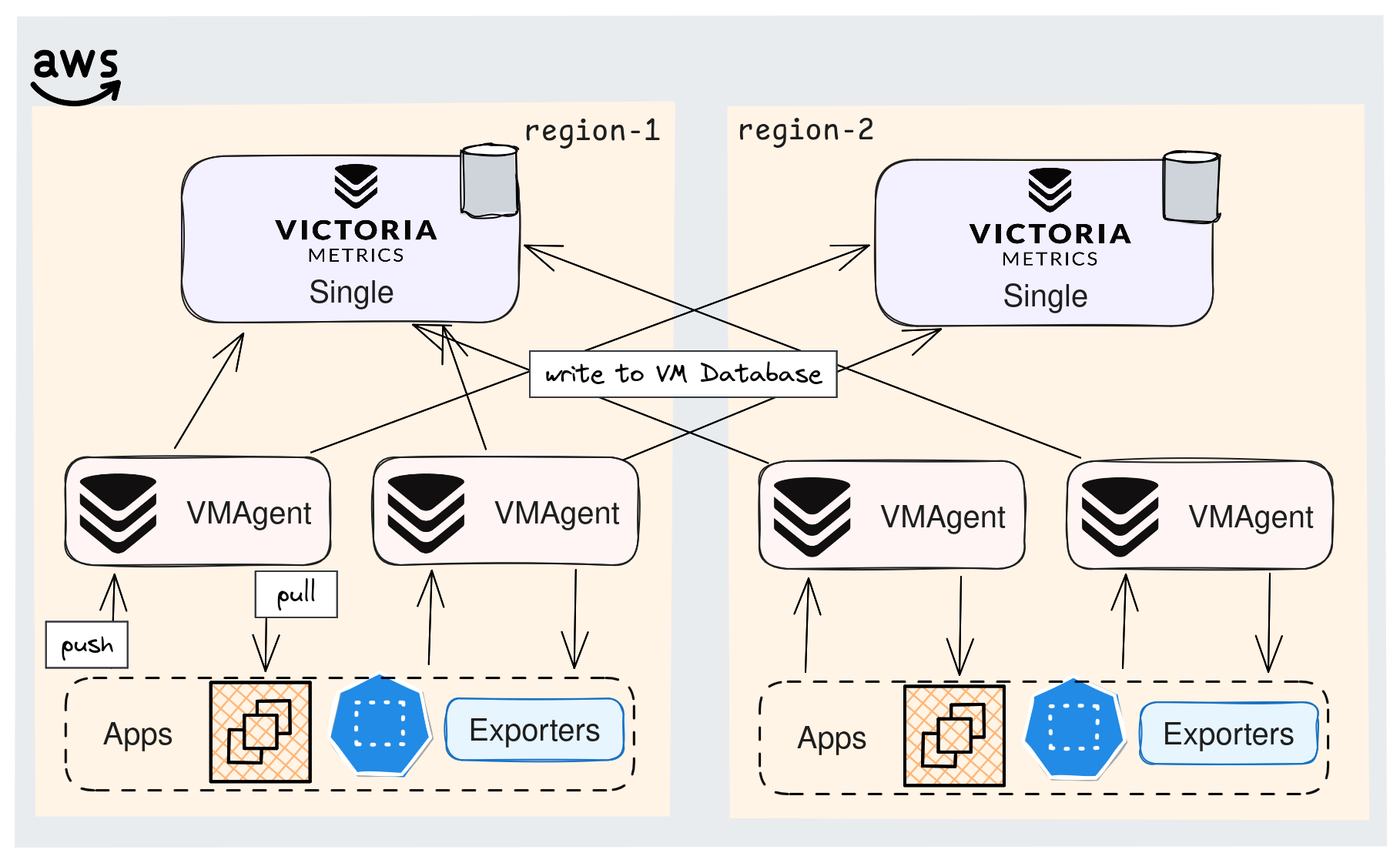
Pour ne jamais perdre de vue ce qui se passe sur nos applications, la solution de supervision doit toujours rester opérationnelle. Pour cela, tous les composants de VictoriaMetrics peuvent être configurés en haute disponibilité. En fonction du niveau de redondance souhaité, plusieurs options s'offrent à nous.
La plus simple est d'envoyer les données à deux instances Single, les données sont ainsi dupliquées à 2 endroits. De plus, on peut envisager de déployer ces instances dans deux régions différentes.
Il est aussi recommandé de redonder les agents VMAgent qui vont scraper les mêmes services, afin de s'assurer qu'aucune donnée ne soit perdue.
Dans une telle architecture, étant donné que plusieurs VMAgents envoient des données et scrappent les mêmes services, on se retrouve avec des métriques en double. La De-duplication dans VictoriaMetrics permet de ne conserver qu'une seule version lorsque deux raw samples sont identiques.Un paramètre mérite une attention particulière : -dedup.minScrapeInterval: Seule la version la plus récente sera conservée lorsque raw samples identiques sont trouvés dans cet intervale de temps.
Il est aussi recommandé de :
- Configurer ce paramètre avec une valeur égale au
scrape_intervalque l'on définit dans la configuration Prometheus. - Garder une valeur de
scrape_intervalidentique pour tous les services scrappés.
Le schéma ci-dessous montre l'une des nombreuses combinaisons possibles pour assurer une disponibilité optimale.⚠️ Cependant, il faut tenir compte du surcoût, non seulement pour le stockage et le calcul, mais aussi pour les transferts réseau entre zones/régions. Il est parfois plus judicieux d'avoir une bonne stratégie de sauvegarde et restauration 😅.
Le mode Cluster
Comme mentionné plus tôt, dans la plupart des cas, le mode Single est largement suffisant. Il a l'avantage d'être simple à maintenir et, avec du scaling vertical, il permet de répondre à quasiment tous les cas d'usage. Il existe aussi un mode Cluster, qui n'est pertinent que dans deux cas précis :
- Besoin de multitenant. Par exemple pour isoler plusieurs équipes ou clients.
- Si les limites du scaling vertical sont atteintes.
Ma configuration permet de choisir entre l'un ou l'autre des modes:
observability/base/victoria-metrics-k8s-stack/kustomization.yaml
1resources:
2...
3
4 - vm-common-helm-values-configmap.yaml
5 # Choose between single or cluster helm release
6
7 # VM Single
8 - helmrelease-vmsingle.yaml
9 - httproute-vmsingle.yaml
10
11 # VM Cluster
12 # - helmrelease-vmcluster.yaml
13 # - httproute-vmcluster.yaml
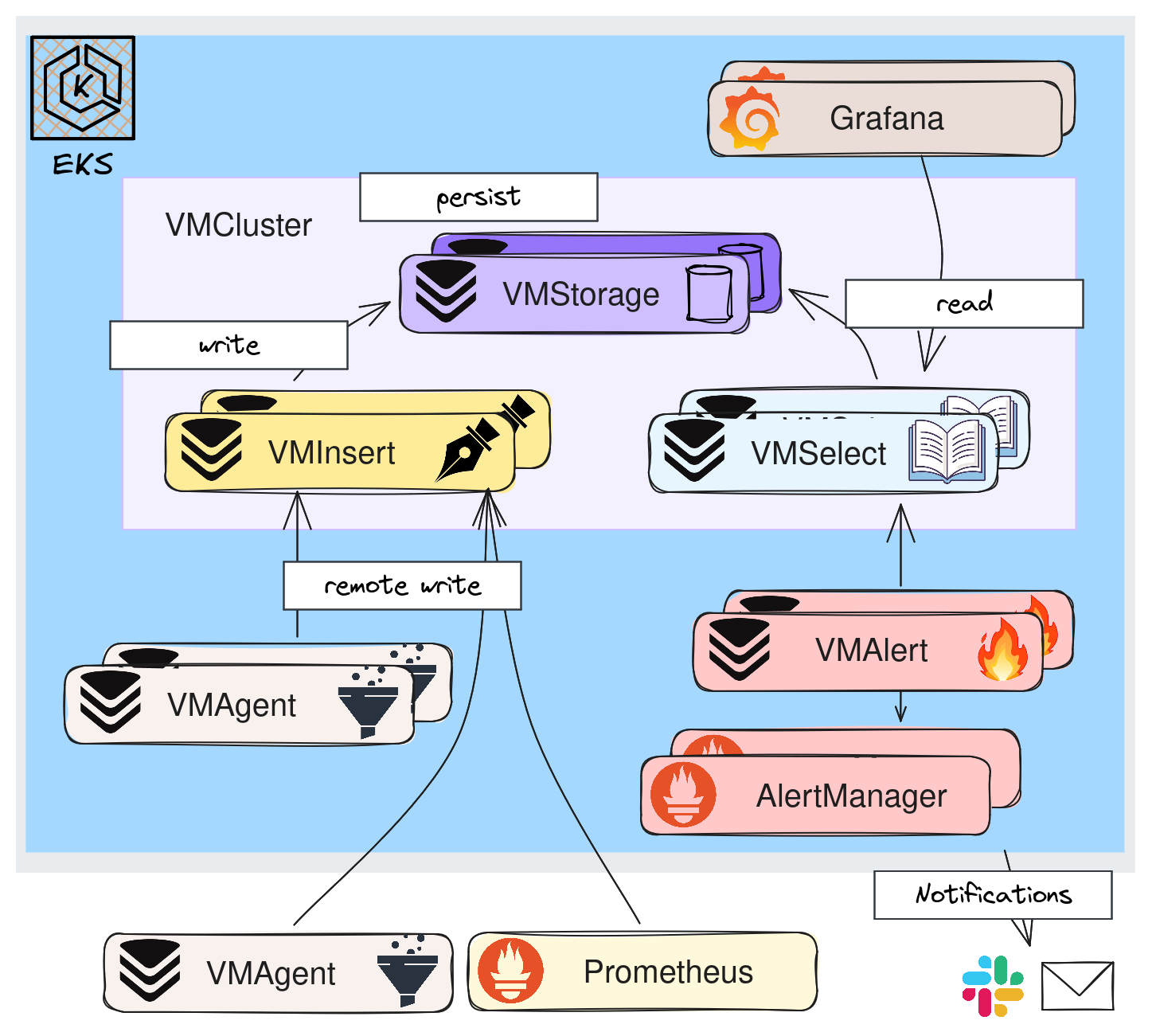
Dans ce mode, on va séparer les fonctions de lecture, écriture et de stockage en 3 services bien distincts.
✏️ VMInsert: Répartit les données sur les instances de VMStorage en utilisant du consistent hashing basé sur la time series (combinaison du nom de la métrique et de ses labels).
💾 VMStorage: Est chargé d'écrire les données sur disque et de retourner les données demandées par VMSelect.
📖 VMSelect: Pour chaque requête va récupérer les données sur les VMStorages.
L'intérêt principal de ce mode est évidemment de pouvoir adapter le scaling en fonction du besoin. Par exemple, si on a besoin de plus de capacité en écriture on va ajouter des replicas VMInsert.
Le paramètre initial, qui permet d'avoir un niveau de redondance minimum est replicationFactor à 2. Voici un extrait des values Helm pour le mode cluster.
observability/base/victoria-metrics-k8s-stack/helmrelease-vmcluster.yaml
1 vmcluster:
2 enabled: true
3 spec:
4 retentionPeriod: "10d"
5 replicationFactor: 2
6 vmstorage:
7 storage:
8 volumeClaimTemplate:
9 storageClassName: "gp3"
10 spec:
11 resources:
12 requests:
13 storage: 10Gi
14 resources:
15 limits:
16 cpu: "1"
17 memory: 1500Mi
18 affinity:
19 podAntiAffinity:
20 requiredDuringSchedulingIgnoredDuringExecution:
21 - labelSelector:
22 matchExpressions:
23 - key: "app.kubernetes.io/name"
24 operator: In
25 values:
26 - "vmstorage"
27 topologyKey: "kubernetes.io/hostname"
28 topologySpreadConstraints:
29 - labelSelector:
30 matchLabels:
31 app.kubernetes.io/name: vmstorage
32 maxSkew: 1
33 topologyKey: topology.kubernetes.io/zone
34 whenUnsatisfiable: ScheduleAnyway
35 vmselect:
36 storage:
37 volumeClaimTemplate:
38 storageClassName: "gp3"
ℹ️ On notera que certains paramètres font partie des bonnes pratiques Kubernetes, notamment lorsque l'on utilise Karpenter: topologySpreadConstraints permet de répartir sur différentes zones, podAntiAffinity pour éviter que 2 pods pour le même service se retrouvent sur le même noeud.
🛠️ La configuration
Ok, c'est cool, VictoriaMetrics est maintenant déployé 👏. Il est temps de configurer la supervision de nos applications, et pour ça, on va s'appuyer sur le pattern opérateur de Kubernetes. Concrètement, cela signifie que l'on va déclarer des ressources personnalisées (Custom Resources) qui seront interprétées par VictoriaMetrics Operator pour configurer et gérer VictoriaMetrics.
Le Helm chart qu’on a utilisé ne déploie pas directement VictoriaMetrics, mais il installe principalement l’opérateur. Cet opérateur se charge ensuite de créer et de gérer des custom resources comme VMSingle ou VMCluster, qui déterminent comment VictoriaMetrics est déployé et configuré en fonction des besoins.
Le rôle de VMServiceScrape est de définir où aller chercher les métriques pour un service donné. On s’appuie sur les labels Kubernetes pour identifier le bon service et le bon port.
observability/base/victoria-metrics-k8s-stack/vmservicecrapes/karpenter.yaml
1apiVersion: operator.victoriametrics.com/v1beta1
2kind: VMServiceScrape
3metadata:
4 name: karpenter
5 namespace: karpenter
6spec:
7 selector:
8 matchLabels:
9 app.kubernetes.io/name: karpenter
10 endpoints:
11 - port: http-metrics
12 path: /metrics
13 namespaceSelector:
14 matchNames:
15 - karpenter
Nous pouvons vérifier que les paramètres sont bien configurés grâce à kubectl
1kubectl get services -n karpenter --selector app.kubernetes.io/name=karpenter -o yaml | grep -A 4 ports
2 ports:
3 - name: http-metrics
4 port: 8000
5 protocol: TCP
6 targetPort: http-metrics
Parfois il n'y pas de service, nous pouvons alors indiquer comment identifier les pods directement avec VMPodScrape.
observability/base/flux-config/observability/vmpodscrape.yaml
1apiVersion: operator.victoriametrics.com/v1beta1
2kind: VMPodScrape
3metadata:
4 name: flux-system
5 namespace: flux-system
6spec:
7 namespaceSelector:
8 matchNames:
9 - flux-system
10 selector:
11 matchExpressions:
12 - key: app
13 operator: In
14 values:
15 - helm-controller
16 - source-controller
17 - kustomize-controller
18 - notification-controller
19 - image-automation-controller
20 - image-reflector-controller
21 podMetricsEndpoints:
22 - targetPort: http-prom
Toutes nos applications ne sont pas forcément déployées sur Kubernetes. La ressource VMScrapeConfig dans VictoriaMetrics permet d'utiliser plusieurs méthodes de "Service Discovery". Cette ressource offre la flexibilité de définir comment scrapper les cibles via différents mécanismes de découverte, tels que les instances EC2 (AWS), les services Cloud ou d'autres systèmes. Dans l'exemple ci-dessous, on utilise le tag personnalisé observability:node-exporter, et on applique des transformations de labels. Ce qui nous permet de récupérer les métriques exposées par les node-exporters installés sur ces instances.
observability/base/victoria-metrics-k8s-stack/vmscrapeconfigs/ec2.yaml
1apiVersion: operator.victoriametrics.com/v1beta1
2kind: VMScrapeConfig
3metadata:
4 name: aws-ec2-node-exporter
5 namespace: observability
6spec:
7 ec2SDConfigs:
8 - region: ${region}
9 port: 9100
10 filters:
11 - name: tag:observability:node-exporter
12 values: ["true"]
13 relabelConfigs:
14 - action: replace
15 source_labels: [__meta_ec2_tag_Name]
16 target_label: ec2_name
17 - action: replace
18 source_labels: [__meta_ec2_tag_app]
19 target_label: ec2_application
20 - action: replace
21 source_labels: [__meta_ec2_availability_zone]
22 target_label: ec2_az
23 - action: replace
24 source_labels: [__meta_ec2_instance_id]
25 target_label: ec2_id
26 - action: replace
27 source_labels: [__meta_ec2_region]
28 target_label: ec2_region
ℹ️ Si on utilisait déjà le Prometheus Operator, la migration vers VictoriaMetrics est très simple car il est compatible avec les CRDs définies par le Prometheus Operator.
📈 Visualiser nos métriques avec l'opérateur Grafana
Il est facile de deviner à quoi sert le Grafana Operator: Utiliser des ressources Kubernetes pour configurer Grafana 😝. Il permet de déployer des instances Grafana, d'ajouter des datasources, d'importer des dashboards de différentes à partir de différentes sources (URL, JSON), de les classer dans des répertoires etc...Il s'agit d'une alternative au fait de tout définir dans le chart Helm ou d'utiliser des configmaps et, selon moi, offre une meilleure lecture. Dans cet exemple, je regroupe l'ensemble des ressources relatives à la supervision de Cilium
1tree infrastructure/base/cilium/
2infrastructure/base/cilium/
3├── grafana-dashboards.yaml
4├── grafana-folder.yaml
5├── httproute-hubble-ui.yaml
6├── kustomization.yaml
7├── vmrules.yaml
8└── vmservicescrapes.yaml
La définition du répertoire est super simple
observability/base/infrastructure/cilium/grafana-folder.yaml
1apiVersion: grafana.integreatly.org/v1beta1
2kind: GrafanaFolder
3metadata:
4 name: cilium
5spec:
6 allowCrossNamespaceImport: true
7 instanceSelector:
8 matchLabels:
9 dashboards: "grafana"
Puis voici une ressource Dashboard qui va chercher la configuration à partir d'un lien HTTP. Nous pouvons aussi utiliser les dashboards disponibles depuis le site de Grafana, en indiquant l'ID approprié ou carrément mettre la définition au format JSON.
observability/base/infrastructure/cilium/grafana-dashboards.yaml
1apiVersion: grafana.integreatly.org/v1beta1
2kind: GrafanaDashboard
3metadata:
4 name: cilium-cilium
5spec:
6 folderRef: "cilium"
7 allowCrossNamespaceImport: true
8 datasources:
9 - inputName: "DS_PROMETHEUS"
10 datasourceName: "VictoriaMetrics"
11 instanceSelector:
12 matchLabels:
13 dashboards: "grafana"
14 url: "https://raw.githubusercontent.com/cilium/cilium/main/install/kubernetes/cilium/files/cilium-agent/dashboards/cilium-dashboard.json"
Notez que j'ai choisi de ne pas utiliser l'opérateur Grafana pour déployer l'instance, mais de garder celle qui a été installée via le Helm chart de VictoriaMetrics. Il faut donc simplement fournir à l'opérateur Grafana les paramètres d'authentification pour qu'il puisse appliquer les modifications sur cette instance.
observability/base/grafana-operator/grafana-victoriametrics.yaml
1apiVersion: grafana.integreatly.org/v1beta1
2kind: Grafana
3metadata:
4 name: grafana-victoriametrics
5 labels:
6 dashboards: "grafana"
7spec:
8 external:
9 url: http://victoria-metrics-k8s-stack-grafana
10 adminPassword:
11 name: victoria-metrics-k8s-stack-grafana-admin
12 key: admin-password
13 adminUser:
14 name: victoria-metrics-k8s-stack-grafana-admin
15 key: admin-user
Enfin nous pouvons utiliser Grafana et explorer nos différents dashboards 🎉!
💭 Dernières remarques
Si l'on se réfère aux différents articles consultés, l'une des principales raisons pour lesquelles migrer ou choisir VictoriaMetrics serait une meilleure performance en règle générale. Cependant il est judicieux de rester prudent car les résultats des benchmarks dépendent de plusieurs facteurs, ainsi que de l'objectif recherché. C'est pourquoi il est fortement conseillé de lancer des tests soit même. VictoriaMetrics propose un jeu de test qui peut être réalisé sur les TSDB compatibles avec Prometheus.
Vous l'aurez compris, aujourd'hui mon choix se porte sur VictoriaMetrics pour la collecte des métriques, car j'apprécie l'architecture modulaire avec une multitude de combinaisons possibles en fonction de l'évolution du besoin. Cependant, une solution utilisant l'opérateur Prometheus fonctionne très bien dans la plupart des cas et a l'intérêt d'être gouverné par une fondation.
Par aileurs, il est important de noter que certaines fonctionnalités ne sont disponibles qu'en version Entreprise, notamment le downsampling qui est fort utile lorsque l'on veut garder une grosse quantité de données sur du long terme.
Dans cet article nous avons surtout pu mettre en évidence la facilité de mise en oeuvre pour obtenir une solution qui permette, d'une part de collecter efficacement les métriques, et de les visualiser. Ceci, toujours en utilisant le pattern operateur Kubernetes qui permet de faire du GitOps, et de déclarer les différents types de ressources au travers de Custom resources. Ainsi Un développeur peut très bien inclure à ses manifests, un VMServiceScrape et une VMRule et, ainsi, inclure la culture de l'observabilité dans les processes de livraisons applicative.
Disposer de métriques c'est bien bien, mais est-ce suffisant? On va essayer d'y répondre dans les prochains articles ...