CloudNativePG: An easy way to run PostgreSQL on Kubernetes

Overview
Kubernetes is now the de facto platform for orchestrating stateless applications. Containers that don't store data can be destroyed and easily recreated elsewhere. On the other hand, running persistent applications in an ephemeral environment can be quite challenging. There is an increasing number of mature cloud-native database solutions (like CockroachDB, TiDB, K8ssandra, Strimzi...) and there are a lot of things to consider when evaluating them:
- How mature is the operator?
- What do the CRDs look like, which options, settings, and status do they expose?
- Which Kubernetes storage APIs does it leverage? (PV/PVC, CSI, snapshots...)
- Can it differentiate HDD and SSD, local/remote storage?
- What happens when something goes wrong: how resilient is the system?
- Backup and recovery: how easy is it to perform and schedule backups?
- What replication and scaling options are available?
- What about connection and concurrency limits, connection pooling, bouncers?
- Observability: what metrics are exposed and how?
I was looking for a solution to host a PostgreSQL database. This database is a requirement for a ticket reservation software named Alf.io that's being used for an upcoming event: The Kubernetes Community Days France. (By the way you're welcome to submit a talk 👐, the CFP closes soon).
I was specifically looking for a cloud-agnostic solution, with emphasis on ease of use. I was already familiar with several Kubernetes operators, and I ended up evaluating a fairly new kid on the block: CloudNativePG.
CloudNativePG is the Kubernetes operator that covers the full lifecycle of a highly available PostgreSQL database cluster with a primary/standby architecture, using native streaming replication.
It has been created by the company EnterpriseDB, who submitted it to the CNCF in order to join the Sandbox projects.
🎯 Our target
I'm going to give you an introduction to the main CloudNativePG features. The plan is to:
- create a PostgreSQL database on a GKE cluster,
- add a standby instance,
- run a few resiliency tests.
We will also see how it behaves in terms of performances and what are the observability tools available. Finally we'll have a look to the backup/restore methods.
In this article, we will create and update everything manually; but in production, we probably should use a GitOps engine, for instance Flux (which has been covered in a previous article).
If you want to see a complete end-to-end example, you can look at the KCD France infrastructure repository.
All the manifests shown in this article can be found in this repository.
☑️ Requirements
📥 Tooling
gcloud SDK: we're going to deploy on Google Cloud (specifically, on GKE) and we will need to create a few resources in our GCP project; so we'll need the Google Cloud SDK and CLI. If needed, you can install and configure it using this documentation.
kubectl plugin: to facilitate cluster management, CloudNativePG comes with a handy
kubectlplugin that gives insights of your PostgreSQL instance and allows to perform some operations. It can be installed using krew as follows:
1kubectl krew install cnpg
☁️ Create the Google cloud requirements
Before creating our PostgreSQL instance, we need to configure a few things:
- We need a Kubernetes cluster. This article assumes that you have already taken care of provisioning a GKE cluster.
- We'll create a bucket to store the backups and WAL files.
- We'll grant permissions to our pods so that they can write to that bucket.
Create the bucket using gcloud CLI
1gcloud storage buckets create --location=eu --default-storage-class=coldline gs://cnpg-ogenki
2Creating gs://cnpg-ogenki/...
3
4gcloud storage buckets describe gs://cnpg-ogenki
5[...]
6name: cnpg-ogenki
7owner:
8 entity: project-owners-xxxx0008
9projectNumber: 'xxx00008'
10rpo: DEFAULT
11selfLink: https://www.googleapis.com/storage/v1/b/cnpg-ogenki
12storageClass: STANDARD
13timeCreated: '2022-10-15T19:27:54.364000+00:00'
14updated: '2022-10-15T19:27:54.364000+00:00'
Now, we're going to give the permissions to the pods (PostgreSQL server) to write/read from the bucket using Workload Identity.
The GKE cluster should be configured with Workload Identity enabled. Check your cluster configuration, you should get something with this command:
1gcloud container clusters describe <cluster_name> --format json --zone <zone> | jq .workloadIdentityConfig
2{
3 "workloadPool": "{{ gcp_project }}.svc.id.goog"
4}
Create a Google Cloud service account
1gcloud iam service-accounts create cloudnative-pg --project={{ gcp_project }}
2Created service account [cloudnative-pg].
Assign the storage.admin permission to the serviceaccount
1gcloud projects add-iam-policy-binding {{ gcp_project }} \
2--member "serviceAccount:cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com" \
3--role "roles/storage.admin"
4[...]
5- members:
6 - serviceAccount:cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com
7 role: roles/storage.admin
8etag: BwXrGA_VRd4=
9version: 1
Allow the Kubernetes service account to impersonate the IAM service account.
ℹ️ ensure you use the proper format serviceAccount:{{ gcp_project }}.svc.id.goog[{{ kubernetes_namespace }}/{{ kubernetes_serviceaccount }}]
1gcloud iam service-accounts add-iam-policy-binding cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com \
2--role roles/iam.workloadIdentityUser --member "serviceAccount:{{ gcp_project }}.svc.id.goog[demo/ogenki]"
3Updated IAM policy for serviceAccount [cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com].
4bindings:
5- members:
6 - serviceAccount:{{ gcp_project }}.svc.id.goog[demo/ogenki]
7 role: roles/iam.workloadIdentityUser
8etag: BwXrGBjt5kQ=
9version: 1
We're ready to create the Kubernetes resources 💪
🔑 Create the users secrets
We need to create the users credentials that will be used during the bootstrap process (more info later on): The superuser and the newly created database owner.
1kubectl create secret generic cnpg-mydb-superuser --from-literal=username=postgres --from-literal=password=foobar --namespace demo
2secret/cnpg-mydb-superuser created
1kubectl create secret generic cnpg-mydb-user --from-literal=username=smana --from-literal=password=barbaz --namespace demo
2secret/cnpg-mydb-user created
🛠️ Deploy the CloudNativePG operator using Helm
CloudNativePG is basically a Kubernetes operator which comes with some CRDs. We'll use the Helm chart as follows
1helm repo add cnpg https://cloudnative-pg.github.io/charts
2
3helm upgrade --install cnpg --namespace cnpg-system \
4--create-namespace charts/cloudnative-pg
5
6kubectl get po -n cnpg-system
7NAME READY STATUS RESTARTS AGE
8cnpg-74488f5849-8lhjr 1/1 Running 0 6h17m
Here are the Custom Resource Definitions installed along with the operator.
1kubectl get crds | grep cnpg.io
2backups.postgresql.cnpg.io 2022-10-08T16:15:14Z
3clusters.postgresql.cnpg.io 2022-10-08T16:15:14Z
4poolers.postgresql.cnpg.io 2022-10-08T16:15:14Z
5scheduledbackups.postgresql.cnpg.io 2022-10-08T16:15:14Z
For a full list of the available parameters for these CRDs please refer to the API reference.
🚀 Create a PostgreSQL server
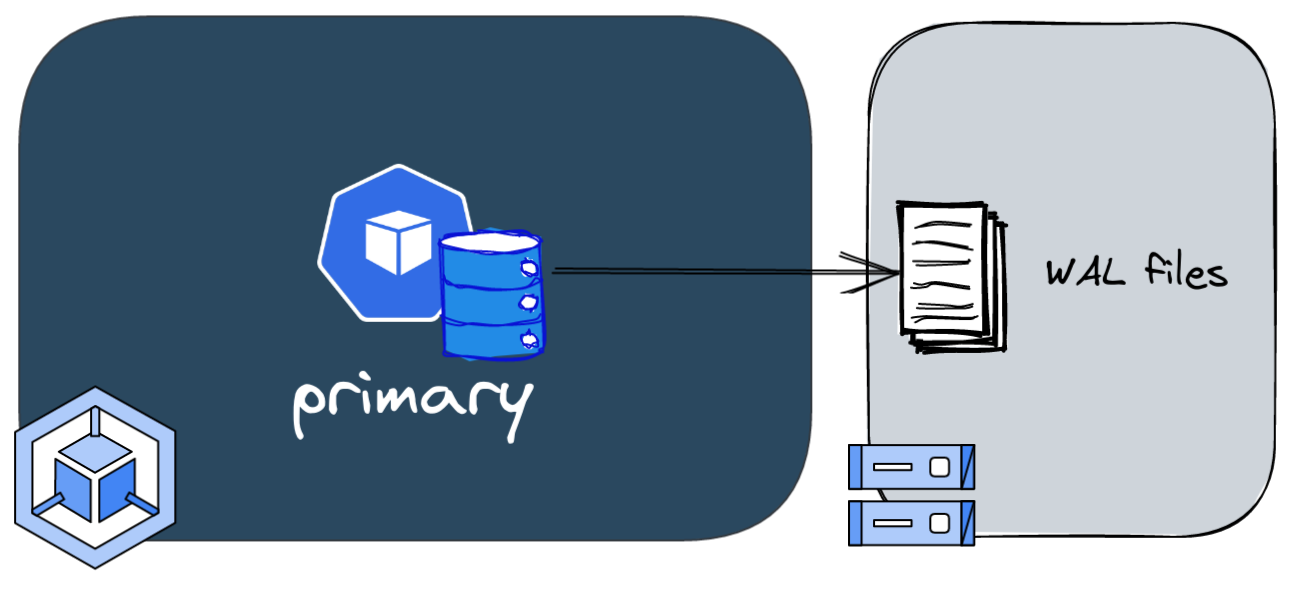
Now we can create our first instance using a custom resource Cluster. The following definition is pretty simple: we want to start a PostgreSQL server, automatically create a database named mydb and configure the credentials based on the secrets created previously.
1apiVersion: postgresql.cnpg.io/v1
2kind: Cluster
3metadata:
4 name: ogenki
5 namespace: demo
6spec:
7 description: "PostgreSQL Demo Ogenki"
8 imageName: ghcr.io/cloudnative-pg/postgresql:14.5
9 instances: 1
10
11 bootstrap:
12 initdb:
13 database: mydb
14 owner: smana
15 secret:
16 name: cnpg-mydb-user
17
18 serviceAccountTemplate:
19 metadata:
20 annotations:
21 iam.gke.io/gcp-service-account: cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com
22
23 superuserSecret:
24 name: cnpg-mydb-superuser
25
26 storage:
27 storageClass: standard
28 size: 10Gi
29
30 backup:
31 barmanObjectStore:
32 destinationPath: "gs://cnpg-ogenki"
33 googleCredentials:
34 gkeEnvironment: true
35 retentionPolicy: "30d"
36
37 resources:
38 requests:
39 memory: "1Gi"
40 cpu: "500m"
41 limits:
42 memory: "1Gi"
Create the namespace where our PostgreSQL instance will be deployed
1kubectl create ns demo
2namespace/demo created
Change the above cluster manifest to fit your needs and apply it.
1kubectl apply -f cluster.yaml
2cluster.postgresql.cnpg.io/ogenki created
You'll notice that the cluster will be in initializing phase. Let's use the cnpg plugin for the first time, it will become our best friend to display a neat view of the cluster's status.
1kubectl cnpg status ogenki -n demo
2Cluster Summary
3Primary server is initializing
4Name: ogenki
5Namespace: demo
6PostgreSQL Image: ghcr.io/cloudnative-pg/postgresql:14.5
7Primary instance: (switching to ogenki-1)
8Status: Setting up primary Creating primary instance ogenki-1
9Instances: 1
10Ready instances: 0
11
12Certificates Status
13Certificate Name Expiration Date Days Left Until Expiration
14---------------- --------------- --------------------------
15ogenki-ca 2023-01-13 20:02:40 +0000 UTC 90.00
16ogenki-replication 2023-01-13 20:02:40 +0000 UTC 90.00
17ogenki-server 2023-01-13 20:02:40 +0000 UTC 90.00
18
19Continuous Backup status
20First Point of Recoverability: Not Available
21No Primary instance found
22Streaming Replication status
23Not configured
24
25Instances status
26Name Database Size Current LSN Replication role Status QoS Manager Version Node
27---- ------------- ----------- ---------------- ------ --- --------------- ----
The first thing that runs under the hood is the bootstrap process. In our example we create a brand new database named mydb with an owner smana and credentials are retrieved from the secret we created previously.
1[...]
2 bootstrap:
3 initdb:
4 database: mydb
5 owner: smana
6 secret:
7 name: cnpg-mydb-user
8[...]
1kubectl get po -n demo
2NAME READY STATUS RESTARTS AGE
3ogenki-1 0/1 Running 0 55s
4ogenki-1-initdb-q75cz 0/1 Completed 0 2m32s
After a few seconds the cluster becomes ready 👏
1kubectl cnpg status ogenki -n demo
2Cluster Summary
3Name: ogenki
4Namespace: demo
5System ID: 7154833472216277012
6PostgreSQL Image: ghcr.io/cloudnative-pg/postgresql:14.5
7Primary instance: ogenki-1
8Status: Cluster in healthy state
9Instances: 1
10Ready instances: 1
11
12[...]
13
14Instances status
15Name Database Size Current LSN Replication role Status QoS Manager Version Node
16---- ------------- ----------- ---------------- ------ --- --------------- ----
17ogenki-1 33 MB 0/17079F8 Primary OK Burstable 1.18.0 gke-kcdfrance-main-np-0e87115b-xczh
There are many ways of bootstrapping your cluster. For instance, restoring a backup into a brand new instance, running SQL scripts... more info here.
🩹 Standby instance and resiliency
In traditional PostgreSQL architectures we usually find an additional component to handle high availability (e.g. Patroni). A specific aspect of the CloudNativePG operator is that it leverages built-in Kubernetes features and relies on a component named Postgres instance manager.
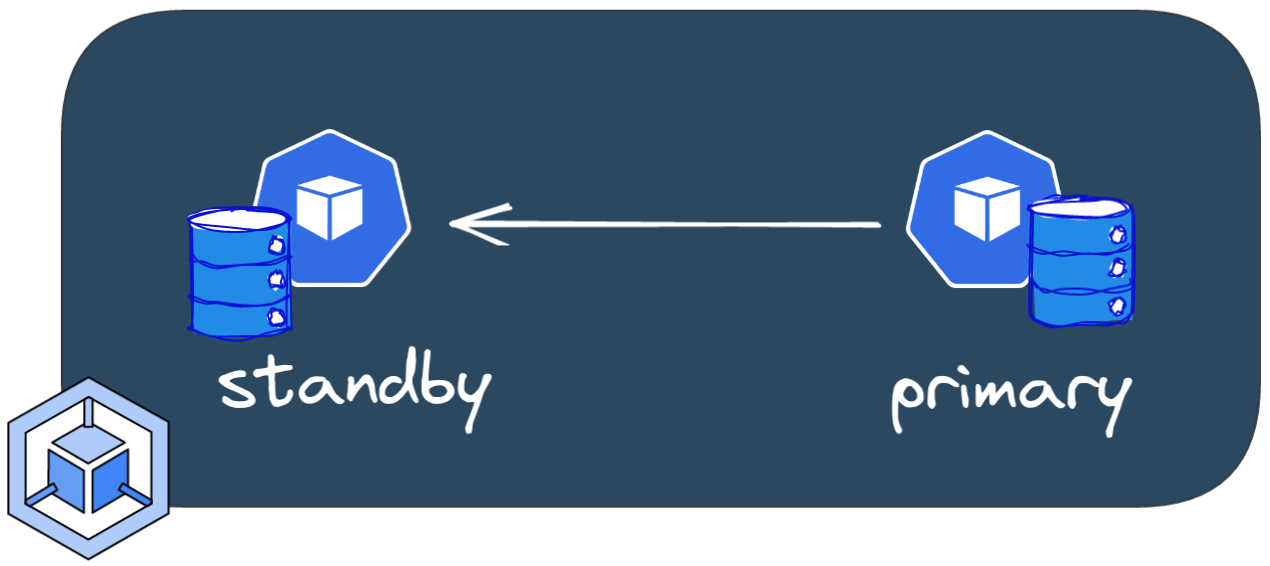
Add a standby instance by setting the number of replicas to 2.
1kubectl edit cluster -n demo ogenki
2cluster.postgresql.cnpg.io/ogenki edited
1apiVersion: postgresql.cnpg.io/v1
2kind: Cluster
3[...]
4spec:
5 instances: 2
6[...]
The operator immediately notices the change, adds a standby instance, and starts the replication process.
1kubectl cnpg status -n demo ogenki
2Cluster Summary
3Name: ogenki
4Namespace: demo
5System ID: 7155095145869606932
6PostgreSQL Image: ghcr.io/cloudnative-pg/postgresql:14.5
7Primary instance: ogenki-1
8Status: Creating a new replica Creating replica ogenki-2-join
9Instances: 2
10Ready instances: 1
11Current Write LSN: 0/1707A30 (Timeline: 1 - WAL File: 000000010000000000000001)
1kubectl get po -n demo
2NAME READY STATUS RESTARTS AGE
3ogenki-1 1/1 Running 0 3m16s
4ogenki-2-join-xxrwx 0/1 Pending 0 82s
After a while (depending on the amount of data to replicate), the standby instance will be up and running and we can see the replication statistics.
1kubectl cnpg status -n demo ogenki
2Cluster Summary
3Name: ogenki
4Namespace: demo
5System ID: 7155095145869606932
6PostgreSQL Image: ghcr.io/cloudnative-pg/postgresql:14.5
7Primary instance: ogenki-1
8Status: Cluster in healthy state
9Instances: 2
10Ready instances: 2
11Current Write LSN: 0/3000060 (Timeline: 1 - WAL File: 000000010000000000000003)
12
13[...]
14
15Streaming Replication status
16Name Sent LSN Write LSN Flush LSN Replay LSN Write Lag Flush Lag Replay Lag State Sync State Sync Priority
17---- -------- --------- --------- ---------- --------- --------- ---------- ----- ---------- -------------
18ogenki-2 0/3000060 0/3000060 0/3000060 0/3000060 00:00:00 00:00:00 00:00:00 streaming async 0
19
20Instances status
21Name Database Size Current LSN Replication role Status QoS Manager Version Node
22---- ------------- ----------- ---------------- ------ --- --------------- ----
23ogenki-1 33 MB 0/3000060 Primary OK Burstable 1.18.0 gke-kcdfrance-main-np-0e87115b-76k7
24ogenki-2 33 MB 0/3000060 Standby (async) OK Burstable 1.18.0 gke-kcdfrance-main-np-0e87115b-xszc
Let's promote the standby instance to primary (perform a Switchover).
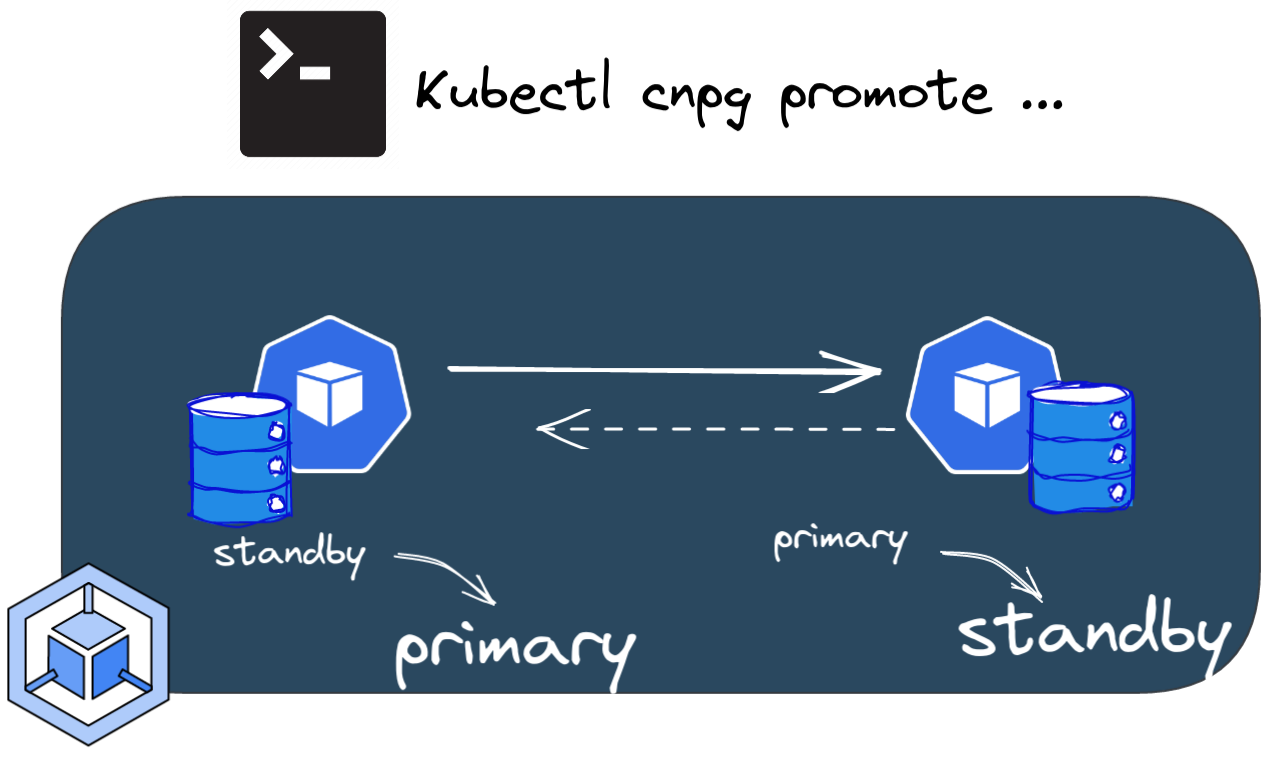
The cnpg plugin allows to do this imperatively by running this command
1kubectl cnpg promote ogenki ogenki-2 -n demo
2Node ogenki-2 in cluster ogenki will be promoted
In my case the switchover was really fast. We can check that the instance ogenki-2 is now the primary and that the replication is done the other way around.
1kubectl cnpg status -n demo ogenki
2[...]
3Status: Switchover in progress Switching over to ogenki-2
4Instances: 2
5Ready instances: 1
6[...]
7Streaming Replication status
8Name Sent LSN Write LSN Flush LSN Replay LSN Write Lag Flush Lag Replay Lag State Sync State Sync Priority
9---- -------- --------- --------- ---------- --------- --------- ---------- ----- ---------- -------------
10ogenki-1 0/4004CA0 0/4004CA0 0/4004CA0 0/4004CA0 00:00:00 00:00:00 00:00:00 streaming async 0
11
12Instances status
13Name Database Size Current LSN Replication role Status QoS Manager Version Node
14---- ------------- ----------- ---------------- ------ --- --------------- ----
15ogenki-2 33 MB 0/4004CA0 Primary OK Burstable 1.18.0 gke-kcdfrance-main-np-0e87115b-xszc
16ogenki-1 33 MB 0/4004CA0 Standby (async) OK Burstable 1.18.0 gke-kcdfrance-main-np-0e87115b-76k7
Now let's simulate a Failover by deleting the primary pod
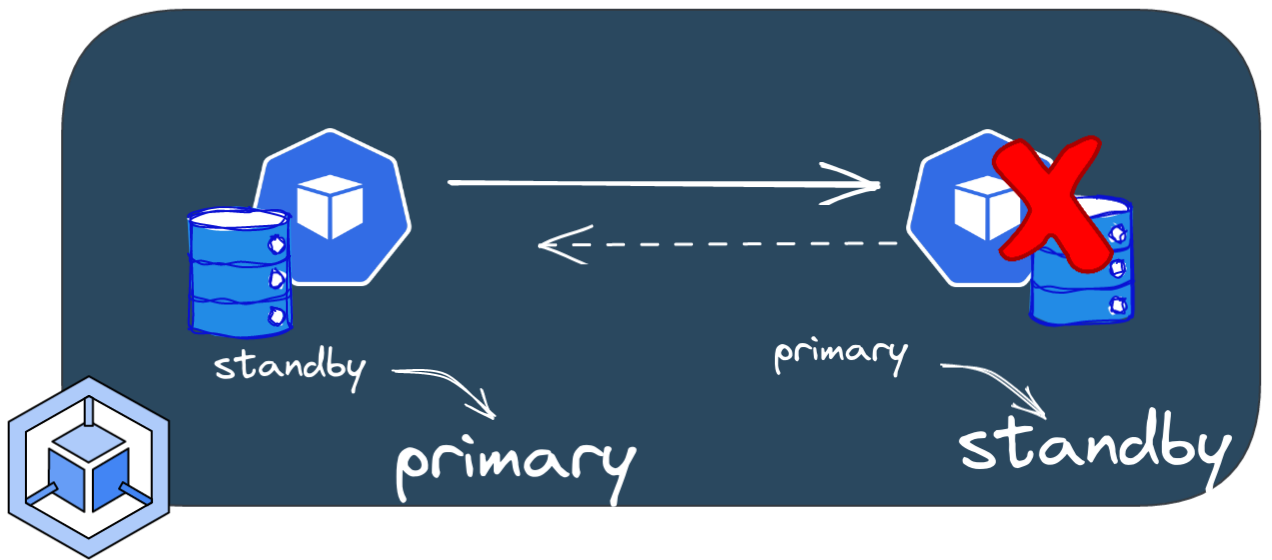
1kubectl delete po -n demo --grace-period 0 --force ogenki-2
2Warning: Immediate deletion does not wait for confirmation that the running resource has been terminated. The resource may continue to run on the cluster indefinitely.
3pod "ogenki-2" force deleted
1Cluster Summary
2Name: ogenki
3Namespace: demo
4System ID: 7155095145869606932
5PostgreSQL Image: ghcr.io/cloudnative-pg/postgresql:14.5
6Primary instance: ogenki-1
7Status: Failing over Failing over from ogenki-2 to ogenki-1
8Instances: 2
9Ready instances: 1
10Current Write LSN: 0/4005D98 (Timeline: 3 - WAL File: 000000030000000000000004)
11
12[...]
13Instances status
14Name Database Size Current LSN Replication role Status QoS Manager Version Node
15---- ------------- ----------- ---------------- ------ --- --------------- ----
16ogenki-1 33 MB 0/40078D8 Primary OK Burstable 1.18.0 gke-kcdfrance-main-np-0e87115b-76k7
17ogenki-2 - - - pod not available Burstable - gke-kcdfrance-main-np-0e87115b-xszc
After a few seconds, the cluster becomes healthy again
1kubectl get cluster -n demo
2NAME AGE INSTANCES READY STATUS PRIMARY
3ogenki 13m 2 2 Cluster in healthy state ogenki-1
So far so good, we've been able to test the high availability and the experience is pretty smooth 😎.
👁️ Monitoring
We're going to use Prometheus Stack. We won't cover its installation in this article. If you want to see how to install it "the GitOps way" you can check this example.
To scrape our instance's metrics, we need to create a PodMonitor.
1apiVersion: monitoring.coreos.com/v1
2kind: PodMonitor
3metadata:
4 labels:
5 prometheus-instance: main
6 name: cnpg-ogenki
7 namespace: demo
8spec:
9 namespaceSelector:
10 matchNames:
11 - demo
12 podMetricsEndpoints:
13 - port: metrics
14 selector:
15 matchLabels:
16 postgresql: ogenki
We can then add the Grafana dashboard available here.

Finally, you may want to configure alerts and you can create a PrometheusRule using these rules.
🔥 Performances and benchmark
Update: It is now possible to use the cnpg plugin. The following method is deprecated, I'll update it asap.
This is worth running a performance test in order to know the limits of your current server and keep a baseline for further improvements.
When it comes to performance there are many improvement areas we can work on. It mostly depends on the target we want to achieve. Indeed we don't want to waste time and money for performance we'll likely never need.
Here are the main things to look at:
- PostgreSQL configuration tuning
- Compute resources (cpu and memory)
- Disk type IOPS, local storage (local-volume-provisioner),
- Dedicated disks for WAL and PG_DATA
- Connection pooling PGBouncer. The CloudNativePG comes with a CRD
Poolerto handle that. - Database optimization, analyzing the query plans using explain, use the extension
pg_stat_statement...
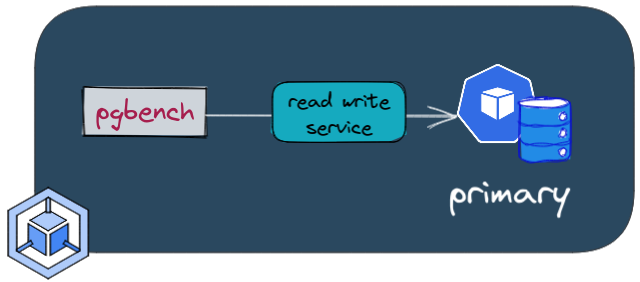
First of all we'll add labels to the nodes in order to run the pgbench command on different machines than the ones hosting the database.
1PG_NODE=$(kubectl get po -n demo -l postgresql=ogenki,role=primary -o jsonpath={.items[0].spec.nodeName})
2kubectl label node ${PG_NODE} workload=postgresql
3node/gke-kcdfrance-main-np-0e87115b-vlzm labeled
4
5
6# Choose any other node different than the ${PG_NODE}
7kubectl label node gke-kcdfrance-main-np-0e87115b-p5d7 workload=pgbench
8node/gke-kcdfrance-main-np-0e87115b-p5d7 labeled
And we'll deploy the Helm chart as follows
1git clone git@github.com:EnterpriseDB/cnp-bench.git
2cd cnp-bench
3
4cat > pgbench-benchmark/myvalues.yaml <<EOF
5cnp:
6 existingCluster: true
7 existingHost: ogenki-rw
8 existingCredentials: cnpg-mydb-superuser
9 existingDatabase: mydb
10
11pgbench:
12 # Node where to run pgbench
13 nodeSelector:
14 workload: pgbench
15 initialize: true
16 scaleFactor: 1
17 time: 600
18 clients: 10
19 jobs: 1
20 skipVacuum: false
21 reportLatencies: false
22EOF
23
24helm upgrade --install -n demo pgbench -f pgbench-benchmark/myvalues.yaml pgbench-benchmark/
There are different services depending on wether you want to read and write or read only.
1kubectl get ep -n demo
2NAME ENDPOINTS AGE
3ogenki-any 10.64.1.136:5432,10.64.1.3:5432 15d
4ogenki-r 10.64.1.136:5432,10.64.1.3:5432 15d
5ogenki-ro 10.64.1.136:5432 15d
6ogenki-rw 10.64.1.3:5432 15d

1kubectl logs -n demo job/pgbench-pgbench-benchmark -f
2Defaulted container "pgbench" out of: pgbench, wait-for-cnp (init), pgbench-init (init)
3pgbench (14.1, server 14.5 (Debian 14.5-2.pgdg110+2))
4starting vacuum...end.
5transaction type: <builtin: TPC-B (sort of)>
6scaling factor: 1
7query mode: simple
8number of clients: 10
9number of threads: 1
10duration: 600 s
11number of transactions actually processed: 545187
12latency average = 11.004 ms
13initial connection time = 111.585 ms
14tps = 908.782896 (without initial connection time)
💽 Backup and Restore
Writing backups and WAL files to the GCP bucket is possible because we gave the permissions using an annotation in the pod's serviceaccount
1 serviceAccountTemplate:
2 metadata:
3 annotations:
4 iam.gke.io/gcp-service-account: cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com
We can first trigger an on-demand backup using the custom resource Backup
1apiVersion: postgresql.cnpg.io/v1
2kind: Backup
3metadata:
4 name: ogenki-now
5 namespace: demo
6spec:
7 cluster:
8 name: ogenki
1kubectl apply -f backup.yaml
2backup.postgresql.cnpg.io/ogenki-now created
3
4kubectl get backup -n demo
5NAME AGE CLUSTER PHASE ERROR
6ogenki-now 36s ogenki completed
If you take a look at the Google Cloud Storage content you'll see an new directory that stores the base backups
1gcloud storage ls gs://cnpg-ogenki/ogenki/base
2gs://cnpg-ogenki/ogenki/base/20221023T130327/
But most of the time we would want to have a scheduled backup. So let's configure a daily schedule.
1apiVersion: postgresql.cnpg.io/v1
2kind: ScheduledBackup
3metadata:
4 name: ogenki-daily
5 namespace: demo
6spec:
7 backupOwnerReference: self
8 cluster:
9 name: ogenki
10 schedule: 0 0 0 * * *
Recoveries can only be done on new instances. Here we'll use the backup we've created previously to bootstrap a new instance with it.
1gcloud iam service-accounts add-iam-policy-binding cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com \
2--role roles/iam.workloadIdentityUser --member "serviceAccount:{{ gcp_project }}.svc.id.goog[demo/ogenki-restore]"
3Updated IAM policy for serviceAccount [cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com].
4bindings:
5- members:
6 - serviceAccount:{{ gcp_project }}.svc.id.goog[demo/ogenki-restore]
7 - serviceAccount:{{ gcp_project }}.svc.id.goog[demo/ogenki]
8 role: roles/iam.workloadIdentityUser
9etag: BwXrs755FPA=
10version: 1
1apiVersion: postgresql.cnpg.io/v1
2kind: Cluster
3metadata:
4 name: ogenki-restore
5 namespace: demo
6spec:
7 instances: 1
8
9 serviceAccountTemplate:
10 metadata:
11 annotations:
12 iam.gke.io/gcp-service-account: cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com
13
14 storage:
15 storageClass: standard
16 size: 10Gi
17
18 resources:
19 requests:
20 memory: "1Gi"
21 cpu: "500m"
22 limits:
23 memory: "1Gi"
24
25 superuserSecret:
26 name: cnpg-mydb-superuser
27
28 bootstrap:
29 recovery:
30 backup:
31 name: ogenki-now
We can notice a first pod that performs the full recovery from the backup.
1kubectl get po -n demo
2NAME READY STATUS RESTARTS AGE
3ogenki-1 1/1 Running 1 (18h ago) 18h
4ogenki-2 1/1 Running 0 18h
5ogenki-restore-1 0/1 Init:0/1 0 0s
6ogenki-restore-1-full-recovery-5p4ct 0/1 Completed 0 51s
Then the new cluster becomes ready.
1kubectl get cluster -n demo
2NAME AGE INSTANCES READY STATUS PRIMARY
3ogenki 18h 2 2 Cluster in healthy state ogenki-1
4ogenki-restore 80s 1 1 Cluster in healthy state ogenki-restore-1
🧹 Cleanup
Delete the cluster
1kubectl delete cluster -n demo ogenki ogenki-restore
2cluster.postgresql.cnpg.io "ogenki" deleted
3cluster.postgresql.cnpg.io "ogenki-restore" deleted
Cleanup the IAM serviceaccount
1gcloud iam service-accounts delete cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com
2You are about to delete service account [cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com].
3
4Do you want to continue (Y/n)? y
5
6deleted service account [cloudnative-pg@{{ gcp_project }}.iam.gserviceaccount.com]
💭 final thoughts
I just discovered CloudNativePG and I only scratched the surface but one thing for sure is that managing PostgreSQL is really made easy. However choosing a database solution is a tough decision. Depending on the use case, the company constraints, the criticity of the application and the ops teams skills, there are plenty of options: Cloud managed databases, traditional bare metal installations, building the architecture with an Infrastructure As Code tool...
We may also consider using Crossplane and composition to give an opinionated way of declaring managed databases in cloud providers but that requires more configuration.
CloudNativePG shines by its simplicity: it is easy to run and easy to understand. Furthermore the documentation is excellent (one of the best I ever seen!), especially for such a young open source project (Hopefuly this will help in the CNCF Sandbox acceptance process 🤞).
If you want to learn more about it, there was a presentation on about it at KubeCon NA 2022.