Dagger: The missing piece of the developer experience?
Overview
Dagger is an open-source project that promises to revolutionize the way continuous integration (CI) pipelines are defined. It was created by the founders of Docker, based on a study of common challenges faced by companies. They identified a lack of effective tooling throughout the development cycle up to production deployment.
One significant issue is the lack of consistency across execution environments. You have probably heard a colleague complain with something like: "It worked fine on my machine! What is this error on the CI?" 😆
By offering a common and centralized method, Dagger could be THE solution to this problem. It aims to improve the local developer experience, enhance collaboration, and accelerate the development cycle.
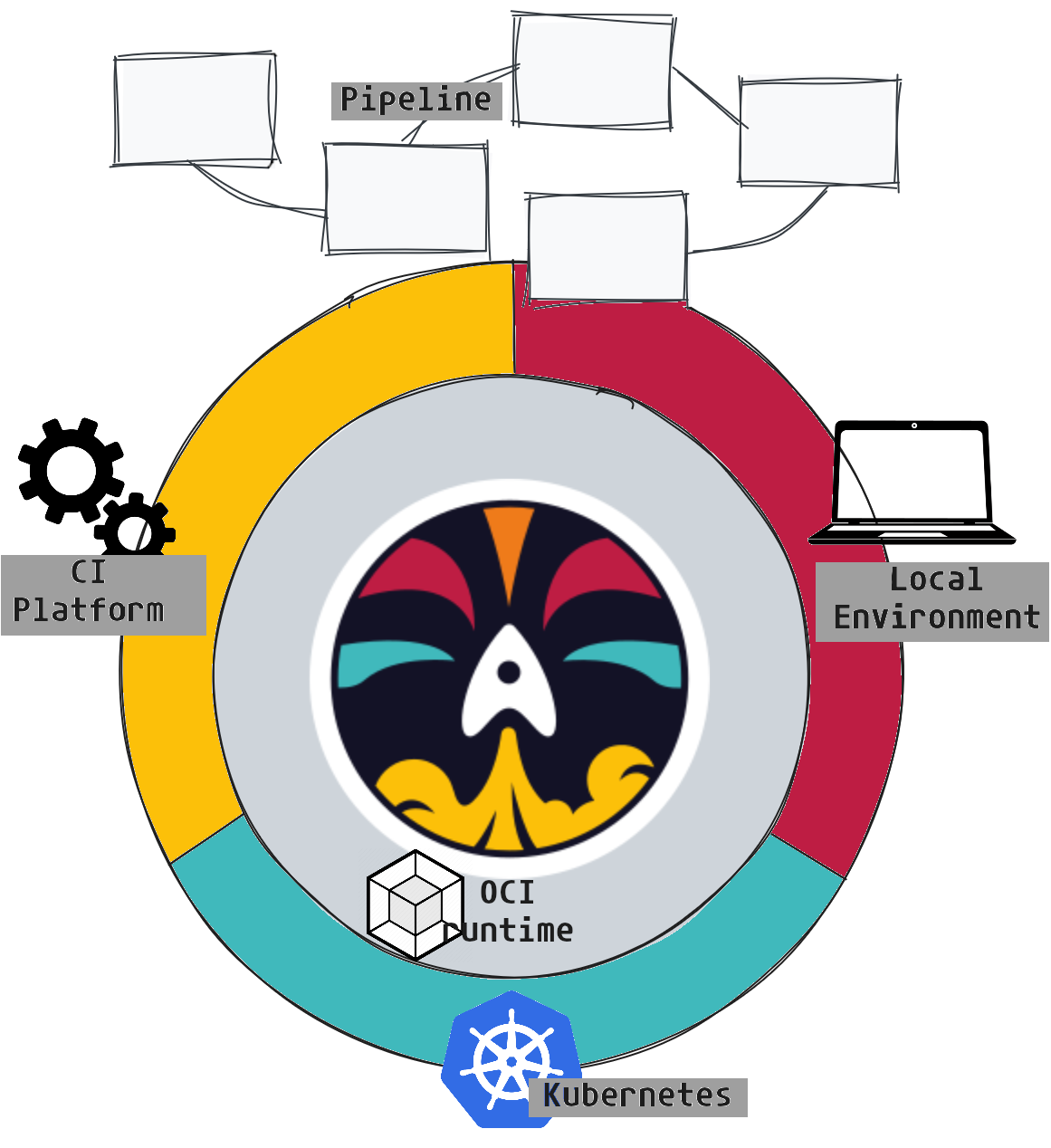
Many of us have used bash scripts, Makefiles, and other traditional methods to automate some actions. However, these solutions can quickly become complex and hard to maintain. Dagger offers a modern and simplified alternative, allowing us to standardize and unify our pipelines regardless of the environment.
So, what are the main features of Dagger, and how can it be used effectively?
🎯 Our target
Here are the points we will cover in this article:
First, we will understand how
Daggerworks and take our get started with it.Next, we will explore concrete use cases for its implementation. We will see how to transform an existing project, and I will also introduce a module that I now use on a daily basis.
Finally, we will describe an effective caching solution that will allow us to scale with Dagger.
🔎 First steps
Basically, Dagger is a tool that allows us to define tasks using our preferred language and make that code portable. In other words, what I run on my machine will be executed in the same way on the CI or on my colleague's computer.
There are two main components involved:
- The Dagger CLI: Our main access point for interacting with various functions and modules, downloading them, and displaying their execution results.
- The Dagger engine: All operations performed with the CLI go through a
GraphQLAPI exposed by a Dagger engine. Each client establishes its own session with the Core API, which offers basicfunctions. These functions can be extended using additional modules (which will be explained later).
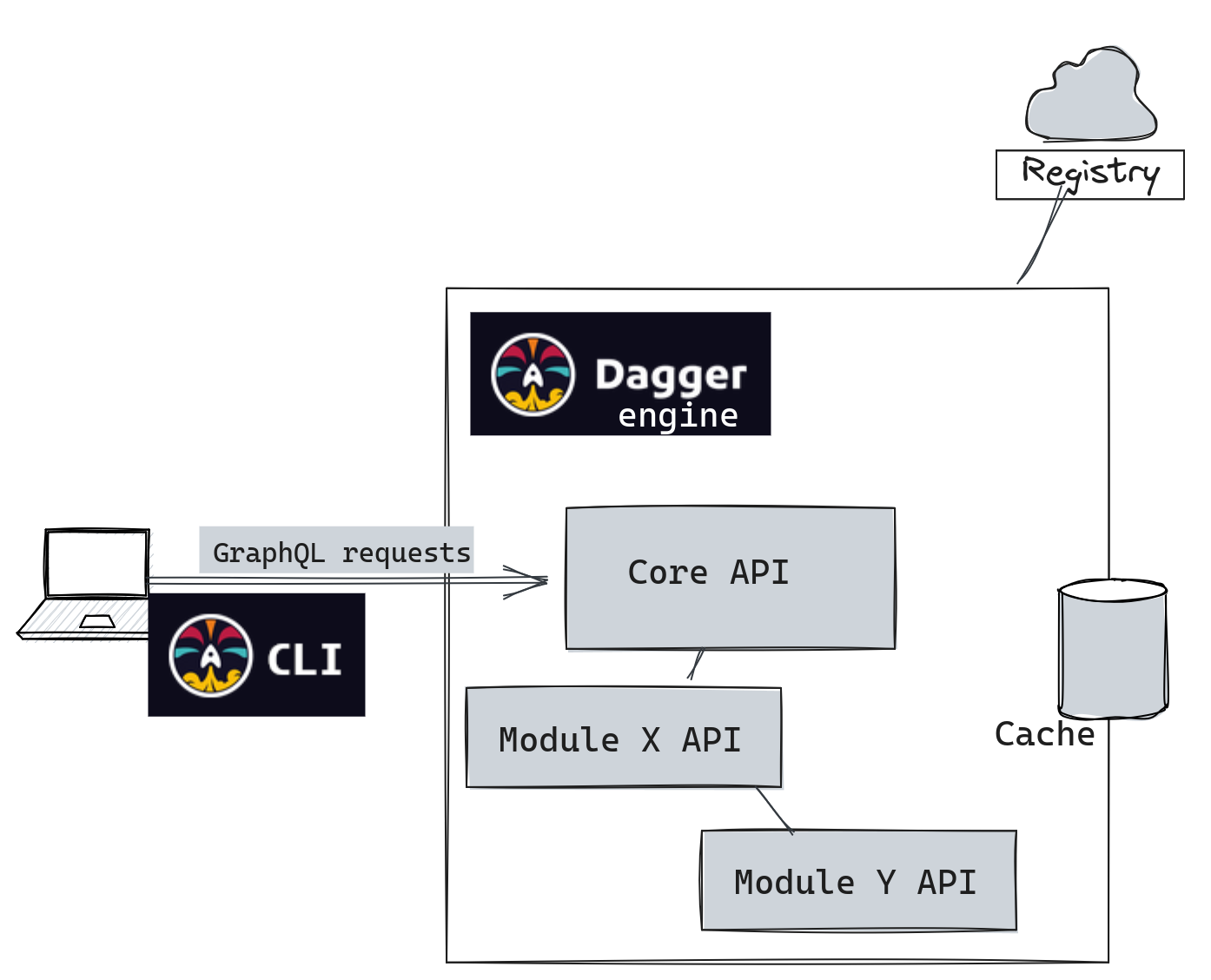
The first time we run Dagger, it pulls and starts a local instance of the Dagger engine. It will therefore run a local API.
1docker ps
2CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
33cec5bf51843 registry.dagger.io/engine:v0.12.1 "dagger-entrypoint.s…" 8 days ago Up 2 hours dagger-engine-ceb38152f96f1298
Let's start by installing the CLI. If you've read my previous articles, you know that I like to use asdf.
1asdf plugin-add dagger
2
3asdf install dagger 0.12.1
4Downloading dagger from https://github.com/dagger/dagger/releases/download/v0.12.1/dagger_v0.12.1_linux_amd64.tar.gz
5
6asdf global dagger 0.12.1
7dagger version
8dagger v0.12.1 (registry.dagger.io/engine) linux/amd64
Let's dive right in and immediately execute a module provided by the community. Suppose we want to scan a git repo and a Docker image with trivy.
The Daggerverse is a platform that allows anyone to share modules. When you have a need, you should have a look at what is already available there.Try by yourself, searching for example golangci, ruff, gptscript, wolfi...
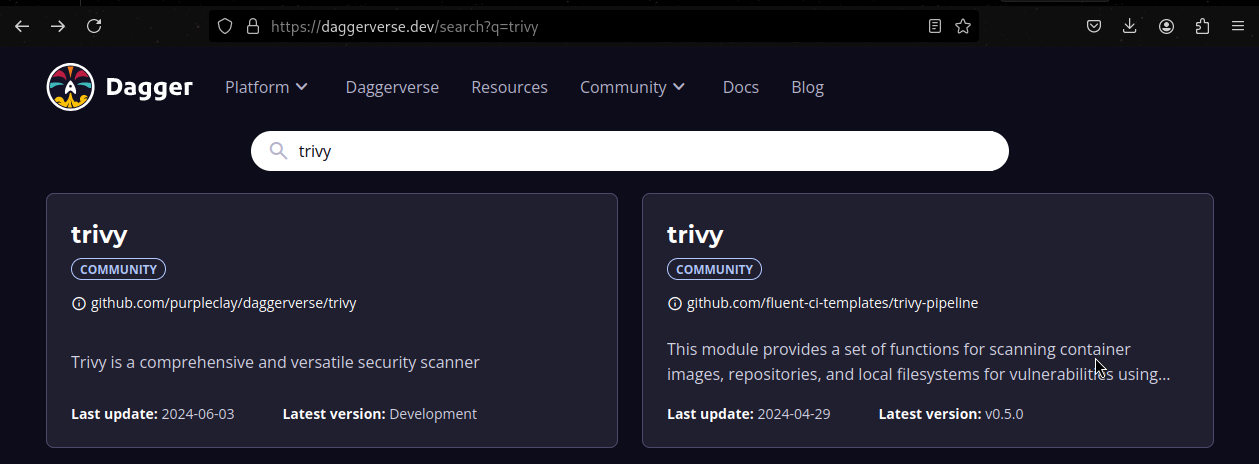
A module is a collection of functions that takes input parameters and returns a response in various forms: output text, terminal execution, service launch, etc. Also, note that all functions are executed in containers.
We can check the available functions in the module using the functions argument.
1TRIVY_MODULE="github.com/purpleclay/daggerverse/trivy@c3f44e0c8a396b2adf024bb862714037ae4cc8e7"
2
3dagger functions -m ${TRIVY_MODULE}
4Name Description
5filesystem Scan a filesystem for any vulnerabilities
6image Scan a published (or remote) image for any vulnerabilities
7image-local Scan a locally exported image for any vulnerabilities
The functions can also take various parameters.
1dagger call -m ${TRIVY_MODULE} filesystem --help
2...
3ARGUMENTS
4 --dir Directory the path to directory to scan [required]
5 --exit-code int the returned exit code when vulnerabilities are detected (0)
6 --format string the type of format to use when generating the compliance report (table)
7 --ignore-unfixed filter out any vulnerabilities without a known fix
8 --scanners string the types of scanner to execute (vuln,secret)
9 --severity string the severity of security issues to detect (UNKNOWN,LOW,MEDIUM,HIGH,CRITICAL)
10 --template string a custom go template to use when generating the compliance report
11 --vuln-type string the types of vulnerabilities to scan for (os,library)
Let's analyze the security level of my local repository 🕵️
1dagger call -m ${TRIVY_MODULE} filesystem --dir "."
2
3scan/go.mod (gomod)
4===================
5Total: 1 (UNKNOWN: 0, LOW: 0, MEDIUM: 1, HIGH: 0, CRITICAL: 0)
6
7┌────────────────────────────────┬────────────────┬──────────┬────────┬───────────────────┬───────────────┬───────────────────────────────────────────────────┐
8│ Library │ Vulnerability │ Severity │ Status │ Installed Version │ Fixed Version │ Title │
9├────────────────────────────────┼────────────────┼──────────┼────────┼───────────────────┼───────────────┼───────────────────────────────────────────────────┤
10│ github.com/vektah/gqlparser/v2 │ CVE-2023-49559 │ MEDIUM │ fixed │ 2.5.11 │ 2.5.14 │ gqlparser denial of service vulnerability via the │
11│ │ │ │ │ │ │ parserDirectives function │
12│ │ │ │ │ │ │ https://avd.aquasec.com/nvd/cve-2023-49559 │
13└────────────────────────────────┴────────────────┴──────────┴────────┴───────────────────┴───────────────┴───────────────────────────────────────────────────┘
Oops! It seems there is a critical vulnerability in my image 😨.
1dagger call -m ${TRIVY_MODULE} image --ref smana/dagger-cli:v0.12.1 --severity CRITICAL
2
3smana/dagger-cli:v0.12.1 (ubuntu 23.04)
4=======================================
5Total: 0 (CRITICAL: 0)
6
7
8usr/local/bin/dagger (gobinary)
9===============================
10Total: 1 (CRITICAL: 1)
11
12┌─────────┬────────────────┬──────────┬────────┬───────────────────┬─────────────────┬────────────────────────────────────────────────────────────┐
13│ Library │ Vulnerability │ Severity │ Status │ Installed Version │ Fixed Version │ Title │
14├─────────┼────────────────┼──────────┼────────┼───────────────────┼─────────────────┼────────────────────────────────────────────────────────────┤
15│ stdlib │ CVE-2024-24790 │ CRITICAL │ fixed │ 1.22.3 │ 1.21.11, 1.22.4 │ golang: net/netip: Unexpected behavior from Is methods for │
16│ │ │ │ │ │ │ IPv4-mapped IPv6 addresses │
17│ │ │ │ │ │ │ https://avd.aquasec.com/nvd/cve-2024-24790 │
18└─────────┴────────────────┴──────────┴────────┴───────────────────┴─────────────────┴────────────────────────────────────────────────────────────┘
That's already super cool to benefit from numerous sources 🤩! These modules can be used directly or become a valuable source of inspiration for our future pipelines.
After this brief introduction, let's move on to real use cases by starting to add functions to an existing git repository.
🦋 Daggerize an existing project
 | Let's take an existing demo project, a simple web server with a function that stores words in a database. We will gradually transform this project by injecting Dagger into it 💉.This iterative, step-by-step approach can also be applied to larger projects to progressively integrate Dagger. |
Our first function 👶
Our priority will be to test the code using the go test command.
Let's start by initializing the git repo to generate the required directory structure for executing Dagger functions.
1git clone https://github.com/Smana/golang-helloworld.git
2cd golang-helloworld
3dagger init --sdk=go
1ls -l dagger*
2.rw-r--r-- 101 smana 28 Jun 21:54 dagger.json
3
4dagger:
5.rw------- 25k smana 28 Jun 21:54 dagger.gen.go
6drwxr-xr-x - smana 28 Jun 21:54 internal
7.rw------- 1.4k smana 28 Jun 21:54 main.go
The init command generates a main.go file containing example functions that we will completely replace with the following code:
1package main
2
3import (
4 "context"
5)
6
7type GolangHelloworld struct{}
8
9// Test runs the tests for the GolangHelloworld project
10func (m *GolangHelloworld) Test(ctx context.Context, source *Directory) (string, error) {
11 ctr := dag.Container().From("golang:1.22")
12 return ctr.
13 WithWorkdir("/src").
14 WithMountedDirectory("/src", source).
15 WithExec([]string{"go", "test", "./..."}).
16 Stdout(ctx)
17}
This is a very simple function:
- The function, called
Test, takes asourcedirectory as a parameter. - We use a
golang:1.22image. - The code from the given directory is mounted in the
/srcfolder of the container. - Then, we run the
go test ./...command on the source directory. - Finally, we retrieve the test results (stdout).
It is sometimes necessary to run the following command to update the Dagger files (dependencies, etc.).
1dagger develop
Let's test our code!
1dagger call test --source "."
2? helloworld/cmd/helloworld [no test files]
3? helloworld/dagger [no test files]
4? helloworld/dagger/internal/dagger [no test files]
5? helloworld/dagger/internal/querybuilder [no test files]
6? helloworld/dagger/internal/telemetry [no test files]
7ok helloworld/internal/server 0.004s
ℹ️ The first run takes time because it downloads the image and installs the Go dependencies, but subsequent runs are much faster. We will discuss about caching later in this article.
What about my docker-compose? 🐳
In this demo repository we used to run Docker Compose in order to test the application locally.
The docker-compose up --build command performs several actions:it builds the Docker image using the local Dockerfile, then starts two containers: one for the application and one for the database. It also enables communication between these two containers.
1docker ps
2CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
3a1673d56f9c8 golang-helloworld-app "/app/main" 3 seconds ago Up 3 seconds 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp golang-helloworld-app-1
4bb3dee1305dc postgres:16 "docker-entrypoint.s…" 3 seconds ago Up 3 seconds 0.0.0.0:5432->5432/tcp, :::5432->5432/tcp golang-helloworld-database-1
You can then access the application and store words in the database.
1curl -X POST -d '{"word":"foobar"}' -H "Content-Type: application/json" http://localhost:8080/store
2
3curl http://localhost:8080/list
4["foobar"]
How to achieve the same with Dagger?
First, we will build the image:
1// Build the Docker container
2func (m *GolangHelloworld) Build(ctx context.Context, source *Directory) *Container {
3 // build the binary
4 builder := dag.Container().
5 From(golangImage).
6 WithDirectory("/src", source).
7 WithWorkdir("/src").
8 WithEnvVariable("CGO_ENABLED", "0").
9 WithExec([]string{"go", "build", "-o", "helloworld", "cmd/helloworld/main.go"})
10
11 // Create the target image with the binary
12 targetImage := dag.Container().
13 From(alpineImage).
14 WithFile("/bin/helloworld", builder.File("/src/helloworld"), ContainerWithFileOpts{Permissions: 0700, Owner: "nobody"}).
15 WithUser("nobody:nobody").
16 WithEntrypoint([]string{"/bin/helloworld"})
17
18 return targetImage
19}
This code demonstrates the use of "multi-stage build" to optimize the security and size of the image. This method allows us to include only what is necessary in the final image, thereby reducing the attack surface and the image size.
Next, we need a PostgreSQL instance. Fortunately, there is a module for that ®!
We will install this dependency to use its functions directly in our code.
1dagger install github.com/quartz-technology/daggerverse/postgres@v0.0.3
The Database() function allows to run a Postrges container.
1...
2 opts := PostgresOpts{
3 DbName: dbName,
4 Cache: cache,
5 Version: "13",
6 ConfigFile: nil,
7 InitScript: initScriptDir,
8 }
9
10...
11 pgCtr := dag.Postgres(pgUser, pgPass, pgPortInt, opts).Database()
Finally, we need to create a link between these two containers. Below, we retrieve the information from the service exposed by the Postgres container in order to use it in our application.
1...
2 pgSvc := pgCtr.AsService()
3
4 pgHostname, err := pgSvc.Hostname(ctx)
5 if err != nil {
6 return nil, fmt.Errorf("could not get postgres hostname: %w", err)
7 }
8
9 return ctr.
10 WithSecretVariable("PGPASSWORD", pgPass).
11 WithSecretVariable("PGUSER", pgUser).
12 WithEnvVariable("PGHOST", pgHostname).
13 WithEnvVariable("PGDATABASE", opts.DbName).
14 WithEnvVariable("PGPORT", pgPort).
15 WithServiceBinding("database", pgSvc).
16 WithExposedPort(8080), nil
17...
Sensitive information can be passed when calling Dagger functions in several ways: environment variables, reading the contents of files, or the output of a command line.
up allows local calls to the services exposed by the container.
1export PGUSER="user"
2export PGPASS="password"
3dagger call serve --pg-user=env:PGUSER --pg-pass=env:PGPASS --source "." as-service up
4
5...
6 ● start /bin/helloworld 30.7s
7 ┃ 2024/06/30 08:27:50 Starting server on :8080
8 ┃ 2024/06/30 08:27:50 Starting server on :8080
Et voilà! We can now test our application locally.
I have intentionally truncated these last excerpts, but I invite you to check out the complete configuration here. There you will find, among other things, the ability to publish the image to a registry.
Additionally, I recommend browsing the Cookbook in the Dagger documentation, where you will find many examples.
🧩 The Kubeconform Module
The first module I wrote is based on a real use case: For several years, I have been using a bash script to validate Kubernetes/Kustomize manifests and the Flux configuration. The idea is to achieve the same results but also go a bit further...
Initializing a module is done as follows:
1dagger init --name=kubeconform --sdk=go kubeconform
Next, we need to decide on the input parameters. For example, I want to be able to choose the version of the Kubeconform binary.
1...
2 // Kubeconform version to use for validation.
3 // +optional
4 // +default="v0.6.6"
5 version string,
6...
The above comments are important: The description will be displayed to the user, and we can make this parameter optional and set a default version.
1dagger call -m github.com/Smana/daggerverse/kubeconform@v0.1.0 validate --help
2Validate the Kubernetes manifests in the provided directory and optional source CRDs directories
3...
4 --version string Kubeconform version to use for validation. (default "v0.6.6")
While developing this module, I went through several iterations and received very useful information on Dagger's Discord. It's a great way to interact with the community.
Let's analyze this, for example:
1kubeconformBin := dag.Arc().
2 Unarchive(dag.HTTP(fmt.Sprintf("https://github.com/yannh/kubeconform/releases/download/%s/kubeconform-linux-amd64.tar.gz", kubeconform_version)).
3 WithName("kubeconform-linux-amd64.tar.gz")).File("kubeconform-linux-amd64/kubeconform")
I use the Arc module to extract an archive retrieved with the HTTP function, and I only take the binary included in this archive. Pretty efficient!
In this other example, I use the Apko module to build
1ctr := dag.Apko().Wolfi([]string{"bash", "curl", "kustomize", "git", "python3", "py3-pip", "yq"}).
2 WithExec([]string{"pip", "install", "pyyaml"})
At the time of writing this article, the Kubeconform module also includes a bit of bash script, primarily to efficiently traverse the directory structure and execute kubeconform.
1 scriptContent := `#!/bin/bash
2...
3`
4
5 // Add the manifests and the script to the container
6 ctr = ctr.
7 WithMountedDirectory("/work", manifests).
8 WithNewFile("/work/run_kubeconform.sh", ContainerWithNewFileOpts{
9 Permissions: 0750,
10 Contents: scriptContent,
11 })
12
13 // Execute the script
14 kubeconform_command := []string{"bash", "/work/run_kubeconform.sh"}
15...
To test and debug the module, we can run it locally on a repository that contains Kubernetes manifests.
1dagger call validate --manifests ~/Sources/demo-cloud-native-ref/clusters --catalog
2...
3Summary: 1 resource found in 1 file - Valid: 1, Invalid: 0, Errors: 0, Skipped: 0
4Validation successful for ./mycluster-0/crds.yaml
5Processing file: ./mycluster-0/flux-config.yaml
6Summary: 1 resource found in 1 file - Valid: 1, Invalid: 0, Errors: 0, Skipped: 0
7Validation successful for ./mycluster-0/flux-config.yaml
For debugging purposes, we can increase the verbosity level as follows. The highest level is -vvv --debug.
1dagger call validate --manifests ~/Sources/demo-cloud-native-ref/clusters --catalog -vvv --debug
2...
309:32:07 DBG new end old="2024-07-06 09:32:07.436103097 +0200 CEST" new="2024-07-06 09:32:07.436103273 +0200 CEST"
409:32:07 DBG recording span span=telemetry.LogsSource/Subscribe id=b3fc48ec7900f581
509:32:07 DBG recording span child span=telemetry.LogsSource/Subscribe parent=ae535768bb2be9d7 child=b3fc48ec7900f581
609:32:07 DBG new end old="2024-07-06 09:32:07.436103273 +0200 CEST" new="2024-07-06 09:32:07.438699251 +0200 CEST"
709:32:07 DBG recording span span="/home/smana/.asdf/installs/dagger/0.12.1/bin/dagger call -m github.com/Smana/daggerverse/kubeconform@v0.1.0 validate --manifests /home/smana/Sources/demo-cloud-native-ref/clusters --catalog -vvv --debug" id=ae535768bb2be9d7
809:32:07 DBG frontend exporting logs logs=4
909:32:07 DBG exporting log span=0xf62760 body=""
1009:32:07 DBG got EOF
1109:32:07 DBG run finished err=<nil>
12
13✔ 609fcdee60c94c07 connect 0.6s
14 ✔ c873c2d69d2b7ce7 starting engine 0.5s
15 ✔ 5f48c41bd0a948ca create 0.5s
16 ✔ dbd62c92c3db105f exec docker start dagger-engine-ceb38152f96f1298 0.0s
17 ┃ dagger-engine-ceb38152f96f1298
18 ✔ 4db8303f1d7ec940 connecting to engine 0.1s
19 ┃ 09:32:03 DBG connecting runner=docker-image://registry.dagger.io/engine:v0.12.1 client=5fa0kn1nc4qlku1erer3868nj
20 ┃ 09:32:03 DBG subscribing to telemetry remote=docker-image://registry.dagger.io/engine:v0.12.1
21 ┃ 09:32:03 DBG subscribed to telemetry elapsed=19.095µs
Starting from version v0.12.x, Dagger introduces an interactive mode. By using the -i or --interactive parameter, it is possible to automatically launch a terminal when the code encounters an error. This allows for performing checks and operations directly within the container.
Additionally, you can insert the execution of Terminal() at any point in the container definition to enter interactive mode at that precise moment.
1...
2 stdout, err := ctr.WithExec(kubeconform_command).
3 Terminal().
4 Stdout(ctx)
5...
With this module, I was also able to add some missing features that are quite useful:
- Convert all CRDs to JSONSchemas to validate 100% of Kubernetes manifests.
- Make it compatible with Flux variable substitutions.
Finally, I was able to share it in the Daggerverse and update my CI workflows on GitHub Actions.
Now that we have an overview of what Dagger is and how to use it, we will explore how to optimize its use in a business setting with a shared cache.
🚀 Rapid Iteration and Collaboration with a shared cache
Using a cache allows you to avoid re-executing steps where the code hasn't changed. During the first run, all steps will be executed, but subsequent runs will only re-run the modified steps, saving a significant amount of time.
Dagger allows caching, at each run, of file manipulation operations, container builds, test executions, code compilation, and volumes that must be explicitly defined in the code.
The following proposal aims to define a shared and remote cache, accessible to all collaborators as well as from the CI. The goal is to speed up subsequent executions, no matter where Dagger is run.
We will see how to put this into practice with:
- GitHub Runners executed privately on our platform (Self-Hosted)
- A centralized Dagger engine
 | This CI on EKS solution is deployed using the repository Cloud Native Ref.I strongly encourage you to check it out, as I cover many topics related to Cloud Native technologies. The initial idea of this project is to be able to quickly start a platform from scratch that applies best practices in terms of automation, monitoring, security, etc. Comments and contributions are welcome 🙏. |
Here is how the CI components interact, with Dagger playing a central role thanks to the shared cache.
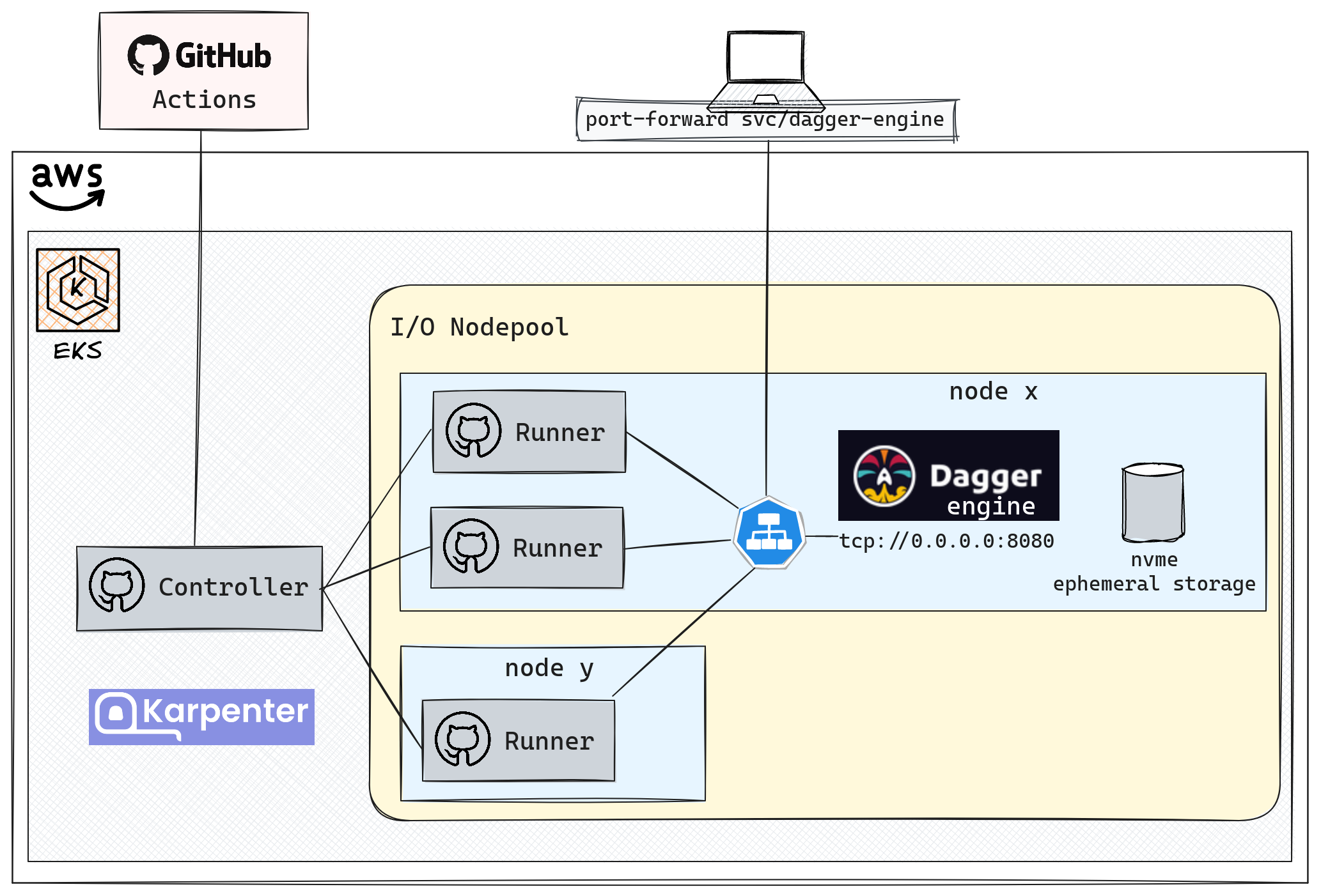
🤖 GitHub Actions and Self-Hosted Runners
Dagger integrates well with most CI platforms. Indeed we just need to run a dagger command. In this article, we use the Action for GitHub Actions.
1 kubernetes-validation:
2 name: Kubernetes validation ☸
3 runs-on: ubuntu-latest
4 steps:
5 - name: Checkout
6 uses: actions/checkout@v4
7
8 - name: Validate Flux clusters manifests
9 uses: dagger/dagger-for-github@v6
10 with:
11 version: "latest"
12 verb: call
13 module: github.com/Smana/daggerverse/kubeconform@kubeconform/v0.1.0
14 args: validate --manifests "./clusters" --catalog
This job downloads the source code from the git repo and runs the kubeconform module. While this works very well, it is important to note that this job runs on runners provided by GitHub on their infrastructure.
GitHub self-hosted runners are machines that you configure to run GitHub Actions workflows on your own infrastructure, rather than using runners hosted by GitHub. They offer more control and flexibility, allowing you to customize the execution environment according to your specific needs. This can lead to improved performance and allows secure access to private resources.
A Scale set is a group of GitHub runners that share a common configuration:
.github/workflows/ci.yaml
1apiVersion: helm.toolkit.fluxcd.io/v2
2kind: HelmRelease
3metadata:
4 name: dagger-gha-runner-scale-set
5spec:
6 releaseName: dagger-gha-runner-scale-set
7...
8 values:
9 runnerGroup: "default"
10 githubConfigUrl: "https://github.com/Smana/demo-cloud-native-ref"
11 githubConfigSecret: gha-runner-scale-set
12 maxRunners: 5
13
14 containerMode:
15 type: "dind"
- This
scale setis configured for the Cloud Native Ref repo. - It requires a secret where the parameters of the
GitHub Appare configured. dindindicates the mode used to launch the containers. ⚠️ However, be cautious in terms of security: Dagger must run as a root user and have elevated privileges in order to control containers, volumes, networks, etc. (More information here).
☸️ EKS Considerations
There are several approaches when it comes to cache optimization, each with its own pros and cons. There are really interesting discussions about running Dagger at scale here. I made some choices that I believe are a good compromise between availability and performance. Here are the main points:
The Dagger Engine: A single pod exposes an HTTP service.
Specific Node Pool: A node pool with constraints to obtain local NVME disks.
1 - key: karpenter.k8s.aws/instance-local-nvme 2 operator: Gt 3 values: ["100"] 4 - key: karpenter.k8s.aws/instance-category 5 operator: In 6 values: ["c", "i", "m", "r"] 7 taints: 8 - key: ogenki/io 9 value: "true" 10 effect: NoScheduleContainer Mount Points: When a node starts, it runs the
/usr/bin/setup-local-disks raid0command. This command prepares the disks by creating a raid0 array and mounts the container file systems on it. Thus, all this space is directly accessible from the pod!
⚠️ Note that this is an ephemeral volume: data is lost when the pod is stopped. We make use of this rapid storage for the Dagger cache.
1...
2 - name: varlibdagger
3 ephemeral:
4 volumeClaimTemplate:
5 spec:
6 accessModes: ["ReadWriteOnce"]
7 resources:
8 requests:
9 storage: 10Gi
10 - name: varrundagger
11 ephemeral:
12 volumeClaimTemplate:
13 spec:
14 accessModes: ["ReadWriteOnce"]
15 resources:
16 requests:
17 storage: 90Gi
18...
1kubectl exec -ti -n tooling dagger-engine-c746bd8b8-b2x6z -- /bin/sh
2/ # df -h | grep nvme
3/dev/nvme3n1 9.7G 128.0K 9.7G 0% /var/lib/dagger
4/dev/nvme2n1 88.0G 24.0K 88.0G 0% /run/buildkit
Best Practices with Karpenter: To optimize the availability of the Dagger engine, we configured it with a Pod Disruption Budget and the annotation
karpenter.sh/do-not-disrupt: "true". Additionally, it is preferable to useOn-demandinstances, which we could consider reserving from AWS to obtain a discount.Network Policies: Since the runners can execute any code, it is highly recommended to limit network traffic to the bare minimum, for both the self-hosted runners and the Dagger engine. Furthermore, this is worth noting that Dagger currently listens using plain HTTP.
To test this, we will run a job that creates a container and installs many relatively heavy packages. The idea is to simulate a build which takes a few minutes.
1 test-cache:
2 name: Testing in-cluster cache
3 runs-on: dagger-gha-runner-scale-set
4 container:
5 image: smana/dagger-cli:v0.12.1
6 env:
7 _EXPERIMENTAL_DAGGER_RUNNER_HOST: "tcp://dagger-engine:8080"
8 cloud-token: ${{ secrets.DAGGER_CLOUD_TOKEN }}
9
10 steps:
11 - name: Simulate a build with heavy packages
12 uses: dagger/dagger-for-github@v6
13 with:
14 version: "latest"
15 verb: call
16 module: github.com/shykes/daggerverse.git/wolfi@dfb1f91fa463b779021d65011f0060f7decda0ba
17 args: container --packages "python3,py3-pip,go,rust,clang"
ℹ️ Accessing the remote Dagger engine endpoint is controlled by the environment variable _EXPERIMENTAL_DAGGER_RUNNER_HOST
During the first run, the job takes 3min and 37secs.

However, any subsequent execution will be much faster (10secs)! 🎉 🚀 🥳

Locally 💻, I can also benefit from this cache by configuring my environment like this:
1kubectl port-forward -n tooling svc/dagger-engine 8080
2_EXPERIMENTAL_DAGGER_RUNNER_HOST="tcp://127.0.0.1:8080"
My local tests will also be accessible by the CI, and another developer taking over my work won't have to rebuild everything from scratch.
➕ This solution has the huge advantage of ultra fast storage! Additionally, the architecture is very simple: a single Dagger engine with local storage that exposes a service.
➖ ⚠️ However, it's far from perfect: you have to accept that this cache is ephemeral despite the precautions taken to increase the level of availability. Also, you need to consider the cost of an instance that runs all the time; scaling can only be done by using a larger machine.
| Dagger Cloud is an enterprise solution that provides a very neat visualization of pipelines execution, with the ability to browse all steps and quickly identify any issues (see below). It's free for individual use, and I encourage you to try it out.This offering also provides an alternative to the solution proposed above: a distributed cache managed by Dagger. (More information here) |  |
💭 Final Thoughts
This article introduced you to Dagger and its main features that I have used. My experience was limited to the Golang SDK, but the experience should be similar with other languages. I learn new things every day. The initial learning curve can be steep, especially for non-developers like me, but the more I use Dagger in real scenarios, the more comfortable I become. In fact, I've successfully migrated 100% of my CI to Dagger.
Dagger is a relatively new project that evolves quickly, supported by an ever-growing and active community. The scaling issues discussed in this article will likely be improved in the future.
Regarding the modules available in the Daggerverse, it can be challenging to judge their quality. There are no "validated" or "official" modules, so you often need to test several, analyze the code, and sometimes create your own.
I transitioned from Makefile to Task, and now I hope to go further with Dagger. I aim to build more complex pipelines, like restoring and verifying a Vault backup or creating and testing an EKS cluster before destroying it. In any case, Dagger is now part of my toolkit, and you should try it out to form your own opinion! ✅