A few months with Claude Code: tips and workflows that helped me
Overview
This article follows Agentic Coding: concepts and hands-on use cases, where we explored the fundamentals of agentic AI — tokens, MCPs, Skills, Tasks — and two detailed practical examples. Here, we dive into advanced practices: how to get the most out of Claude Code on a daily basis.
As with any tool you adopt, it takes time to refine how you use it. After iterating on my config and workflows, I've found an efficient rhythm with Claude Code. Here's what works for me.
This article will be updated as I discover new things and as tools evolve. Feel free to check back from time to time for new tips.
📜 CLAUDE.md: persistent memory
The CLAUDE.md file is the first optimization lever. These are instructions automatically injected into every conversation. If you don't have one yet, it's the first thing to set up.
Loading hierarchy
Claude Code loads CLAUDE.md files according to a specific hierarchy:
| Location | Scope | Use case |
|---|---|---|
~/.claude/CLAUDE.md | All sessions, all projects | Global preferences (language, commit style) |
./CLAUDE.md | Project (shared via git) | Team conventions, build/test commands |
./CLAUDE.local.md | Project (not versioned) | Personal preferences on this project |
./subfolder/CLAUDE.md | Subtree | Instructions specific to a module |
Files are cumulative: Claude loads all of them from most global to most local. In case of conflict, the most local one wins.
What I put in mine
Here's what the CLAUDE.md for cloud-native-ref actually contains:
- Build/test/lint commands — the first lines, so Claude knows how to validate its work
- Project conventions —
xplane-*prefix for IAM, Crossplane composition structure, KCL patterns - Architecture summary — key folder structure, not a novel
- Common pitfalls — traps Claude keeps falling into if you don't warn it (e.g., wrong default namespace, label format)
What I don't put in it: exhaustive documentation (that's what Skills are for), long code examples (I reference existing files instead), and obvious instructions Claude already knows.
Here's a condensed excerpt from the CLAUDE.md of cloud-native-ref to illustrate:
1## Common Commands
2
3### Terramate Operations
4# Deploy entire platform
5terramate script run deploy
6# Preview changes across all stacks
7terramate script run preview
8# Check for configuration drift
9terramate script run drift detect
10
11## Crossplane Resources
12- **Resource naming**: All Crossplane-managed resources prefixed with `xplane-`
13
14## KCL Formatting Rules
15**CRITICAL**: Always run `kcl fmt` before committing KCL code. The CI enforces strict formatting.
16
17### Avoid Mutation Pattern (Issue #285)
18Mutating dictionaries after creation causes function-kcl to create duplicate resources.
19 # ❌ WRONG - Mutation causes DUPLICATES
20 _deployment = { ... }
21 _deployment.metadata.annotations["key"] = "value" # MUTATION!
22
23 # ✅ CORRECT - Use inline conditionals
24 _deployment = {
25 metadata.annotations = {
26 if _ready:
27 "krm.kcl.dev/ready" = "True"
28 }
29 }
You'll find the three essential ingredients: build/deploy commands first (so Claude knows how to validate its work), naming conventions, and specific pitfalls Claude would keep reproducing if not warned.
Every token in CLAUDE.md is loaded in every conversation. An overly long file wastes precious context. Aim for ~500 lines maximum and move specialized instructions to Skills that only load on demand.
Iterating on CLAUDE.md
Treat CLAUDE.md as a production prompt: iterate on it regularly. The # shortcut lets you ask Claude itself to suggest improvements to your file. You can also use Anthropic's prompt improver to refine the instructions.
🪝 Hooks: my first automation
Hooks are shell commands that run automatically in response to Claude Code events. The key difference with CLAUDE.md: CLAUDE.md instructions are advisory (Claude can ignore them), hooks are deterministic — they always run.
Getting notified when Claude is waiting
The first hook I set up — and the one I recommend to everyone — is the desktop notification. When Claude finishes a task or is waiting for your input, you get a system notification with a sound. No more checking the terminal every 30 seconds.
Configuration in ~/.claude/settings.json:
1{
2 "hooks": {
3 "Notification": [
4 {
5 "matcher": "",
6 "hooks": [
7 {
8 "type": "command",
9 "command": "notify-send 'Claude Code' \"$CLAUDE_NOTIFICATION\" --icon=dialog-information && paplay /usr/share/sounds/freedesktop/stereo/complete.oga"
10 }
11 ]
12 }
13 ]
14 }
15}
On Linux, notify-send is provided by the libnotify package and paplay by pulseaudio-utils (or pipewire-pulse). Other mechanisms exist for macOS (osascript) or other environments — see the hooks documentation for alternatives.
Other possibilities
Hooks cover several events (PreToolUse, PostToolUse, Notification, Stop, SessionStart) and enable things like:
- Auto-format after each edit (e.g.,
gofmton Go files) - Sensitive file protection — a
PreToolUsehook that blocks writes to.env,.pem,.keyfiles (exit code 2 = action blocked) - Audit of executed commands in a log file
I won't detail every variant here — the official hooks documentation does a great job. The key takeaway is that hooks are your deterministic safety net where CLAUDE.md is merely advice.
🧠 Mastering the context window
The context window (200K tokens, up to 1M in beta) is the most critical resource. Once saturated, old information gets compressed and quality degrades. This is THE topic that makes the difference between an efficient user and someone who "loses" Claude after 20 minutes.
/compact with custom instructions
The /compact command compresses conversation history while preserving key decisions. The trick: you can pass focus instructions to keep what matters:
1/compact focus on the Crossplane composition decisions and ignore the debugging steps
This is especially useful after a long debugging session where 80% of the context is noise (failed attempts, stack traces).
/clear strategy
The /clear command resets the context to zero. When to use it?
- Always between two distinct tasks — this is the most important rule
- When Claude starts hallucinating or repeating mistakes
- After a long debugging session (context is polluted with failed attempts)
- When
/contextshows < 20% free space
I've made a habit of starting every new task with a /clear. It seems counterintuitive (you lose context), but in practice it's much more effective than a polluted context.
/statusline: a permanent dashboard
Rather than manually running /context, you can set up a permanent status bar at the bottom of the terminal. The /statusline command accepts a natural language prompt to customize the display. Here's what I use:
1/statusline show current directory, git branch, and context usage percentage.
2Use ANSI colors: green for directory, cyan for git branch, yellow for context
3percentage. Use unicode separators and icons like ⎇ for branch
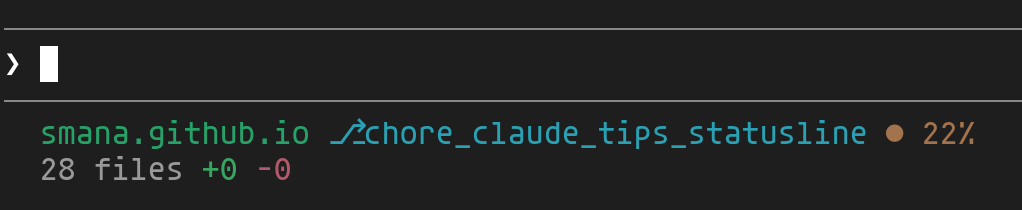
At a glance, you see the current directory, the active git branch, and the context usage percentage — three essential pieces of information to know where you stand without breaking your flow. Especially useful when juggling multiple worktrees or when you want to anticipate a /compact.
This is just my configuration — the prompt is free-form, so you can adapt it to display what matters most to you.
Tool Search: when MCPs eat your context
The problem: each enabled MCP injects its tool definitions into the context. With 6-7 configured MCPs (common in platform engineering), that can represent over 10% of your window — consumed before you even start working.
The solution: enable Tool Search:
1export ENABLE_TOOL_SEARCH=auto:10
With this option, Claude only loads tool definitions when it needs them, rather than keeping them all in memory. The 10 is the threshold (as a percentage of context) at which the mechanism kicks in.
Delegating to subagents
For large exploration tasks (browsing a codebase, searching through logs), Claude can delegate to subagents that have their own isolated context. The condensed result is sent back to the main session — saving precious tokens.
In practice, Claude does this automatically when it deems it relevant (file exploration, broad searches). But you can also guide it explicitly: "use a subagent to explore the networking module structure".
A few simple rules
/clearbetween tasks: Each new task should start with a/clear- Keep CLAUDE.md concise: Every token is loaded in every conversation
- CLIs > MCPs: For mature tools (
kubectl,git,gh...), prefer the CLI directly — LLMs know them perfectly and it avoids loading an MCP /contextto audit: Identify what's consuming context and disable unused MCPs
🔄 Multi-session workflows
Git Worktrees: parallelizing sessions
Rather than juggling branches and stash, I use git worktrees to work on multiple features in parallel with independent Claude sessions.
1# Create two features in parallel
2git worktree add ../worktrees/feature-a -b feat/feature-a
3git worktree add ../worktrees/feature-b -b feat/feature-b
4
5# Launch two separate Claude sessions
6cd ../worktrees/feature-a && claude # Terminal 1
7cd ../worktrees/feature-b && claude # Terminal 2
Each session has its own context and its own memory — no interference between tasks.
Unlike a separate git clone:
- Shared history: A single
.git, commits are immediately visible everywhere - Disk space: ~90% savings (no git object duplication)
- Synchronized branches:
git fetchin one worktree updates all others
When the change is done (PR merged), just go back to the main repo and clean up.
1cd <path_to_main_repo>
2git worktree remove ../worktrees/feature-a
3git branch -d feat/feature-a # after PR merge
Useful commands:
1git worktree list # See all active worktrees
2git worktree prune # Clean up orphaned references
Writer/Reviewer pattern
A pattern I use more and more involves running two sessions in parallel:
| Session | Role | Prompt |
|---|---|---|
| Writer | Implements the code | "Implement feature X according to the spec" |
| Reviewer | Reviews the code | "Review the changes on the feat/X branch, check security and edge cases" |
The reviewer works on the same repo (via worktree or read-only) and provides independent feedback, without the author's bias. This is especially effective for infrastructure changes where a mistake can be costly.
Fan-out with -p
The -p flag (non-interactive prompt) lets you run Claude in headless mode and parallelize tasks:
1# Launch 3 tasks in parallel
2claude -p "Add unit tests for the auth module" &
3claude -p "Document the REST API for the orders service" &
4claude -p "Refactor the billing module to use the new SDK" &
5wait
Each instance has its own context. This is ideal for independent tasks that don't require interaction.
Teams: letting agents work together
The -p approach works great for independent tasks, but sometimes you need agents that talk to each other. That's what teams are for — Claude spawns multiple agents that share a task list, exchange messages, and can wait on each other's results.
This is probably the Opus 4.6 killer feature: you parallelize work, get better performance, and each agent has its own context instead of cramming everything into one session.
Agent teams are still in research preview. To enable them, add this to your settings.json:
1{
2 "env": {
3 "CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS": "1"
4 },
5 "teammateMode": "tmux"
6}
The teammateMode controls how agents are displayed: "tmux" opens each agent in a separate pane (requires tmux), "in-process" runs them all in the same terminal, and "auto" (default) picks automatically based on your environment.
To illustrate the concept, I tried this on a deliberately simple case: analyzing a Crossplane composition. The example is basic, but real-world use cases are plentiful : Troubleshooting an incident by parallelizing log, metrics, and config analysis, creating a new service by splitting code, tests, and documentation across agents, or running a multi-component security audit.
Here, instead of reading the code, then the examples, then writing a summary (all sequentially in the same session), let's create a team as follows:
1Create a team of 3 agents to analyze the Crossplane App composition.
21. code-reader: Read main.k and summarize what resources it creates
32. example-reader: Read all example files and list the configuration options
43. doc-writer: Wait for the other two, then write a combined summary
Here's what it looks like in practice: three tmux panes running side by side — the two readers analyzing the code and examples in parallel, while the doc-writer waits for their output before producing the final summary.
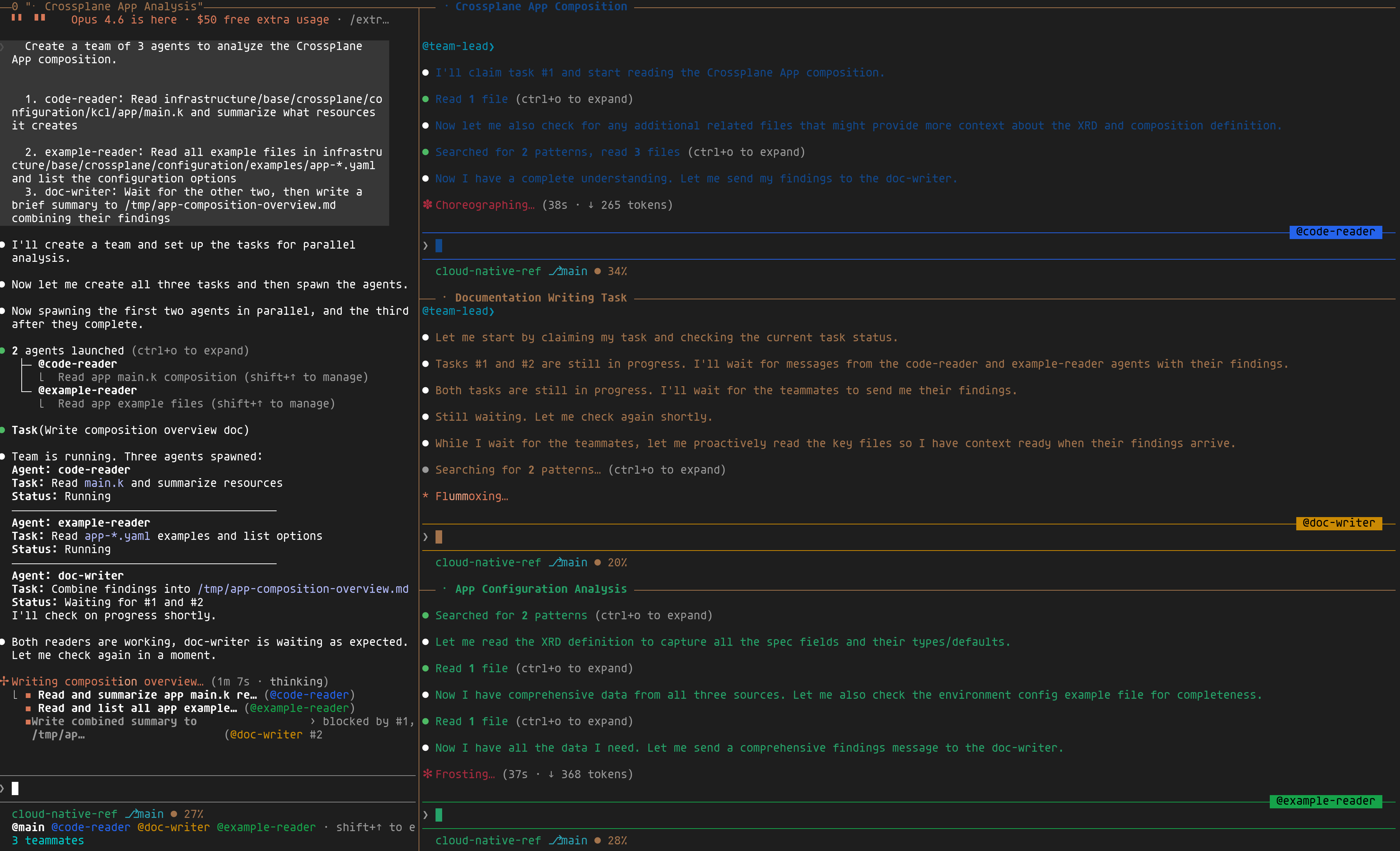
Teams shine when you have independent work that needs to come together — read/analyze/summarize, build/test/document, that kind of thing. For purely sequential tasks, a single session with /clear between steps is simpler.
🖥️ Hybrid IDE + Claude Code workflow
In practice, I alternate between two modes: sometimes pure terminal — old habits — and sometimes hybrid with Cursor for editing and Claude Code in the terminal. The hybrid workflow is clearly more comfortable, and I'm moving towards it more and more.
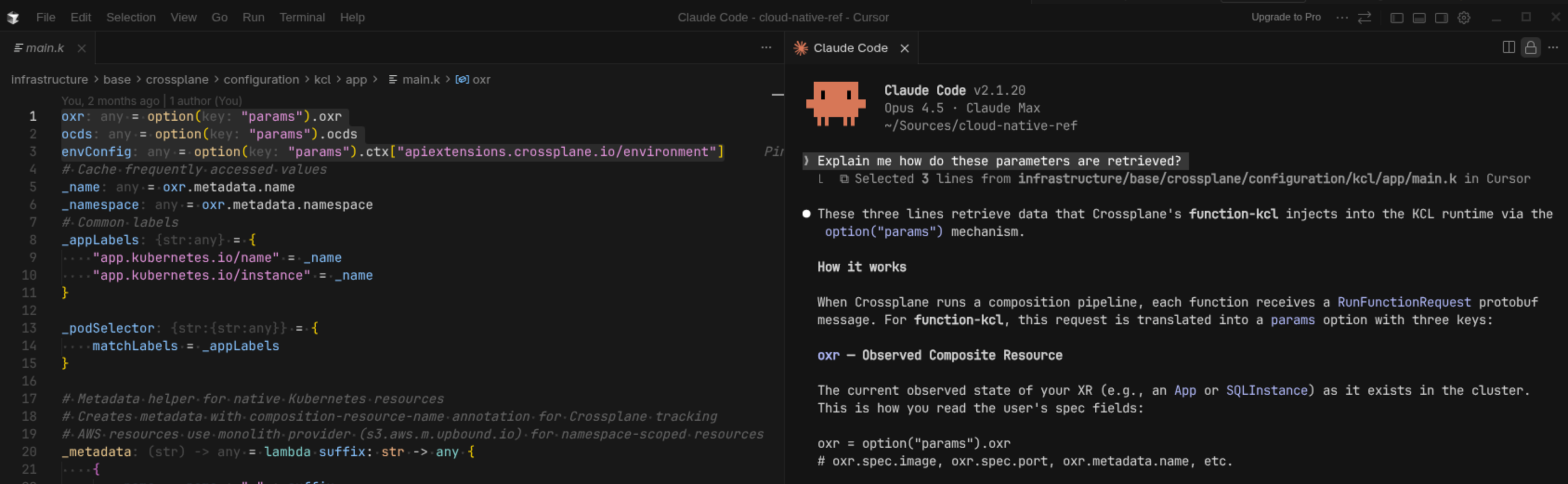
| Need | Tool | Why |
|---|---|---|
| Quick editing, autocomplete | Cursor | Minimal latency, you stay in the flow |
| Refactoring, multi-file debugging | Claude Code | Deep reasoning, autonomous loops |
What I like about hybrid mode: Claude makes changes via the terminal, and I review the diffs in the Cursor interface — much more readable than git diff. Changes appear in real time in the editor, which lets you follow what Claude is doing and step in quickly if needed.
🔌 Plugins
Claude Code has a plugin ecosystem that extends its capabilities. Here are the two I use daily:
Code-Simplifier: cleaning up generated code
The code-simplifier plugin is developed by Anthropic and used internally by the Claude Code team. It automatically cleans up AI-generated code while preserving functionality.
I discovered this plugin recently and intend to make a habit of using it before creating a PR after an intensive session. It runs on Opus and should help reduce the technical debt introduced by AI code — duplicated code, unnecessarily complex structures, inconsistent style.
Claude-Mem: persistent memory across sessions
The claude-mem plugin automatically captures your session context and reinjects it in future sessions. No more re-explaining your project at the start of every conversation.
Its two main strengths:
- Semantic search: easily find information from a past session via the
mem-searchskill - Token consumption optimization: a 3-layer workflow that significantly reduces usage (~10x savings)
Usage examples:
- "Search my sessions for when I debugged Karpenter"
- "Find what I learned about OpenBao PKI last week"
- "Look at my previous work on the App composition"
Claude-mem stores session data locally. For sensitive projects, use <private> tags to exclude information from capture.
⚠️ Anti-patterns
Here are the traps I fell into — and learned to avoid:
| Anti-pattern | Symptom | Solution |
|---|---|---|
| Kitchen sink session | Mixing debugging, features, refactoring in the same session | /clear between each distinct task |
| Correction spiral | Claude fixes a bug, creates another, loops endlessly | Stop, /clear, rephrase with more context |
| Bloated CLAUDE.md | Context consumed from the start, degraded responses | Target ~500 lines, move the rest to Skills |
| Trust-then-verify gap | Accepting code without review, finding bugs in prod | Always read the diff before committing |
| Infinite exploration | Claude browses the entire codebase instead of acting | Give specific files/paths in the prompt |
The correction spiral is by far the most dangerous. A real example: Claude was supposed to add a CiliumNetworkPolicy to a Crossplane composition. First attempt, wrong endpoint selector. It fixes it, but breaks the KCL format. It fixes the format, but reverts to the original bad selector. After 5 iterations and ~40K tokens consumed, I hit /clear and rephrased in 3 lines, specifying the target namespace and an example of an existing policy. Correct result on the first try. The lesson: when Claude loops after 2-3 attempts, it's a sign it's missing context, not persistence. Better to cut and rephrase than to let it spin.
🏁 Conclusion
Over time, I've become increasingly comfortable with Claude Code, and the productivity gains are real. But they come with a lingering concern I can't fully shake: losing control — over the produced code, over the decisions made, over the understanding of what's running in production.
These questions, as well as the methods that help me stay in control, are covered in the first article of this series. If you want to revisit the fundamentals or understand where these reflections come from, I highly recommend it: Agentic Coding: concepts and hands-on use cases.
🔖 References
Official documentation
- Claude Code Documentation — Official guide
- Hooks Documentation — Hooks configuration
Community guides
- How I Use Every Claude Code Feature — Comprehensive guide by sshh
- CC-DevOps-Skills — 31 DevOps skills
Plugins and tools
- Code-Simplifier — AI code cleanup (Anthropic)
- Claude-Mem — Persistent memory across sessions
Previous article
- Agentic Coding: concepts and hands-on use cases — Part 1 of the Agentic AI series